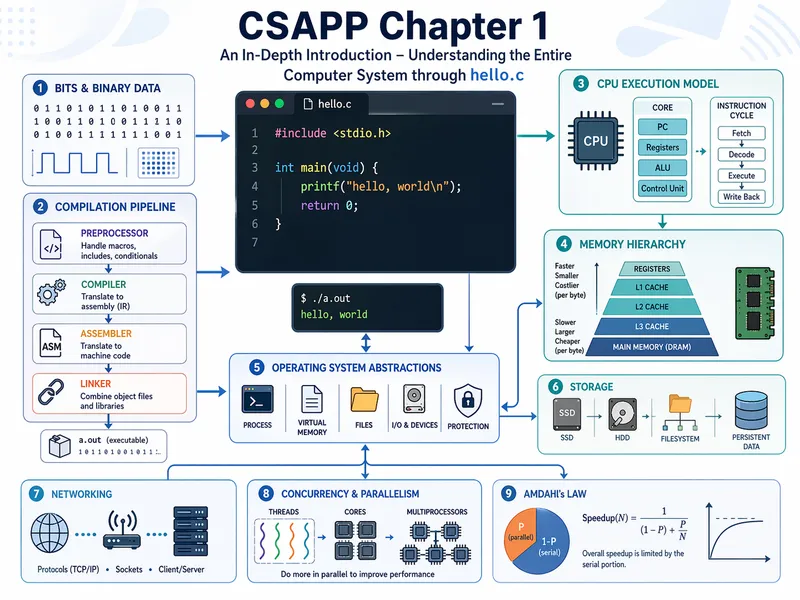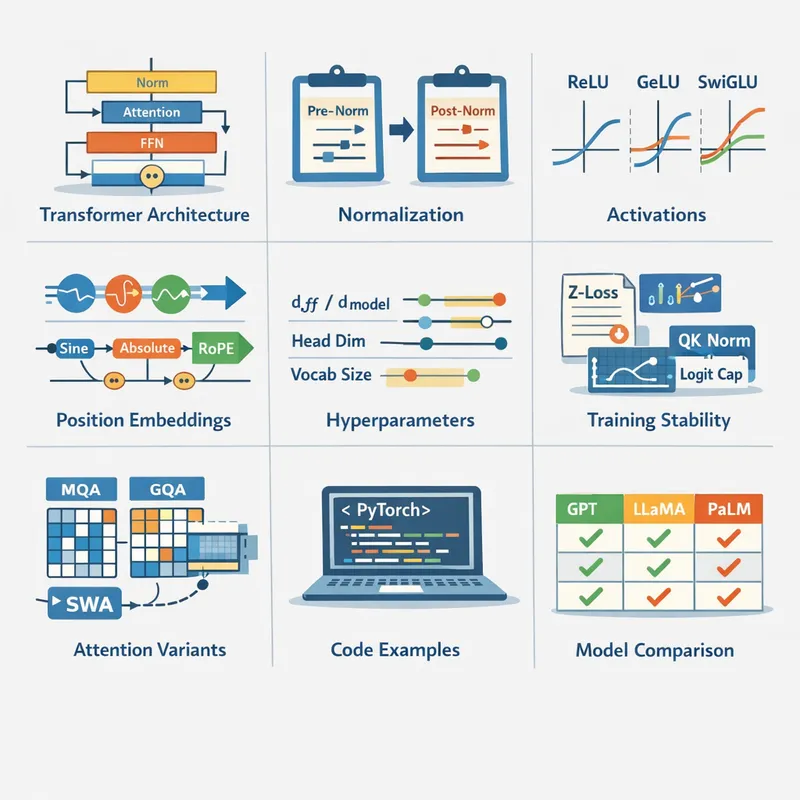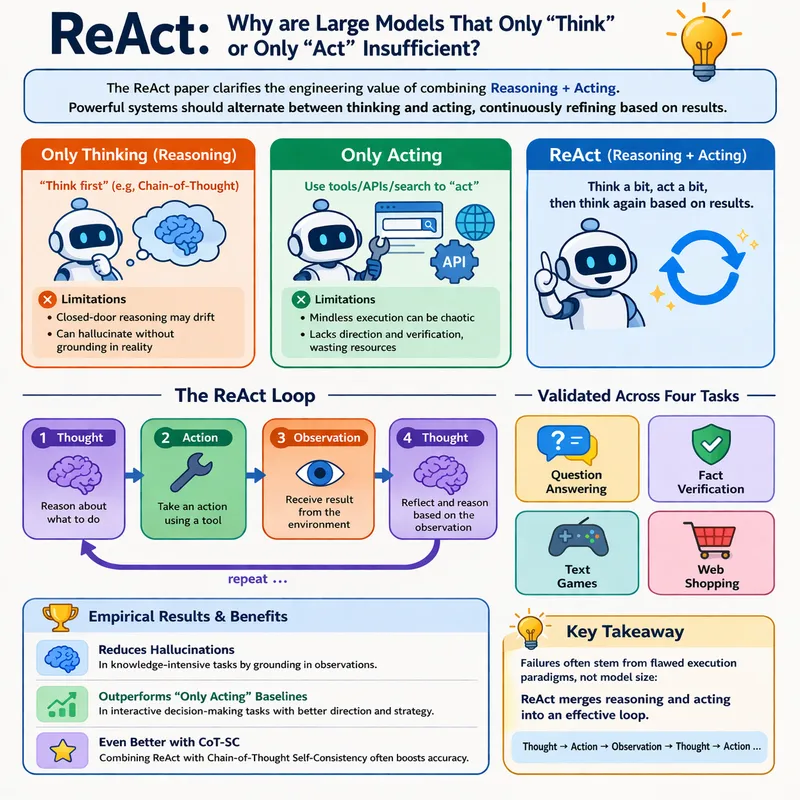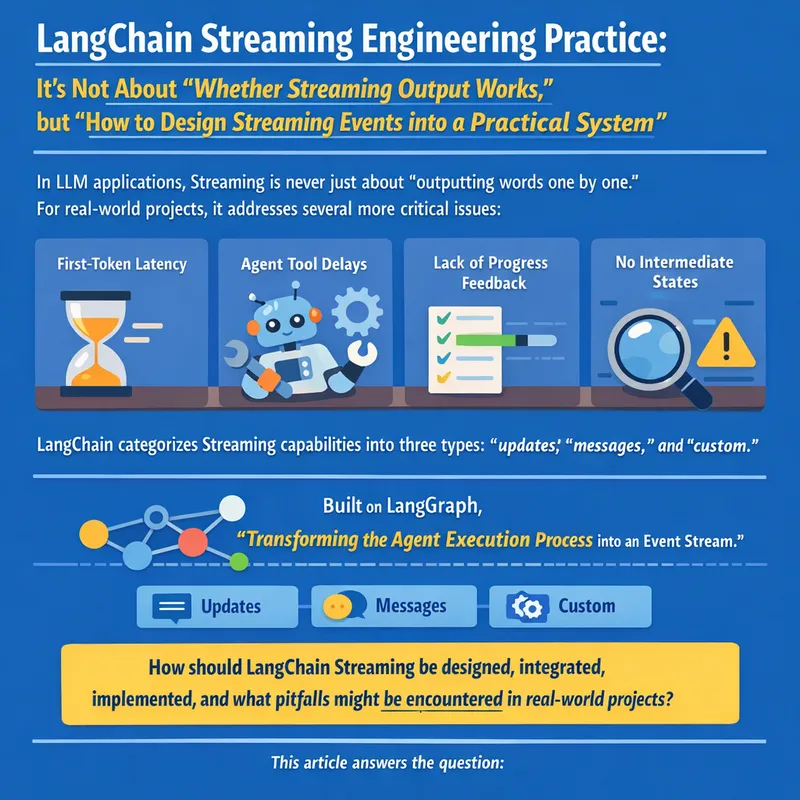
Pattern Recognition and Machine Learning 第一章:模式识别与机器学习导论
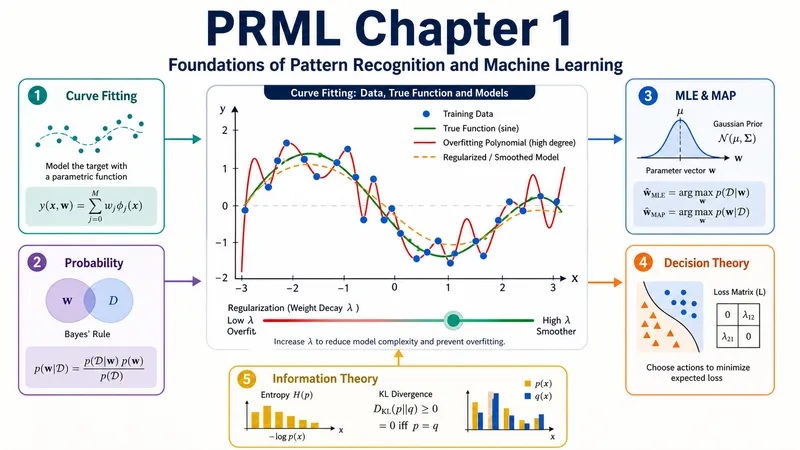
机器学习的大厦,究竟建立在哪些地基之上? 本文是对 Christopher Bishop 经典著作《Pattern Recognition and Machine Learning》第一章的系统性精读笔记。Bishop 在这一章并非只是走马观花地介绍概念,而是以**多项式曲线拟合**这一极简模型为线索,将概率论、统计推断、决策理论与信息论串联成一个严密的整体,揭示出贯穿全书的核心思想。 文章从**过拟合问题**切入——一个 $M=9$ 的多项式为何能完美拟合训练点却在测试集上一塌糊涂?沿着这个问题,我们推导最小二乘的正规方程,发现正则化背后藏着**高斯先验**,最小二乘背后藏着**高斯噪声假设下的最大似然**。这一系列发现将频率派与贝叶斯派的核心分歧具体化:参数到底是未知的常数,还是有自己概率分布的随机变量? 在概率论部分,文章从加法规则和乘法规则出发严格推导贝叶斯定理,并给出均值/方差 MLE 的完整推导与**方差有偏性的数学证明**(贝塞尔校正的来源)。在决策论部分,将最优分类规则与损失矩阵统一在期望损失最小化的框架下,并讨论了三种推断范式(生成模型 / 判别模型 / 判别函数)各自的适用场景。最后,信息论部分揭示了一个深刻的等价关系:**最大似然估计 ≡ 最小化模型分布与数据经验分布之间的 KL 散度**,交叉熵损失函数因此获得了坚实的理论依据。 全文包含完整的数学推导过程和可运行的 Python 代码示例,覆盖第一章全部 6 个小节(含 1.5 决策论与 1.6 信息论),适合有一定线性代数和概率基础、希望深入理解机器学习理论根基的读者。 **关键词**:PRML · 最大似然估计 · 贝叶斯推断 · 过拟合与正则化 · 决策论 · KL 散度 · 信息熵
2026-05-15 · 59 min read