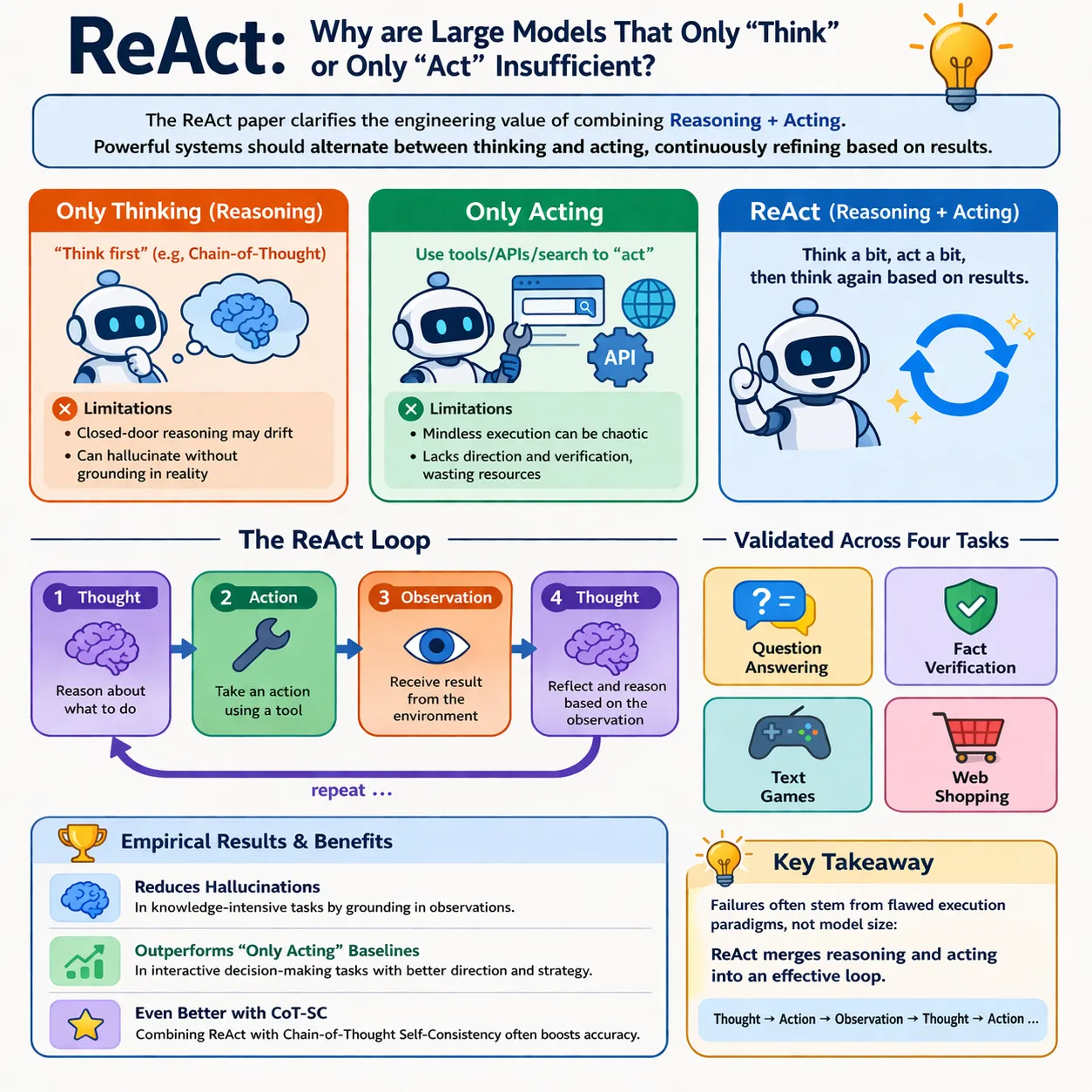
一条路线强调 Reasoning,也就是让模型先“想”,比如 Chain-of-Thought。另一条路线强调 Acting,也就是让模型调用搜索、浏览器、环境 API、工具去“做”。但这篇 ReAct 论文提出了一个很朴素、却非常重要的观点:
真正强的系统,不应该只会想,也不应该只会做,而应该在任务执行过程中交替地“想一下,再做一下,再根据结果继续想”。
这听起来像一句常识,但它在 Agent 设计里其实是一个分水岭。因为很多系统失败,不是模型不够大,而是执行范式有问题: 要么闭门推理,越想越偏; 要么无脑执行,越做越乱。
ReAct 做的事情,本质上就是把这两件事合并成一个循环:
Thought → Action → Observation → Thought → Action ...
论文作者在问答、事实验证、文本游戏、网页购物四类任务上验证了这个范式,并发现: 在知识密集型任务上,ReAct 能减少 hallucination; 在交互决策任务上,ReAct 能明显优于只会行动的基线; 而把 ReAct 和 CoT-SC 结合起来时,效果往往更好。

一、这篇论文到底在解决什么问题?
先别急着看方法,先看痛点。
1. 只会“想”的问题:推理不接地气
Chain-of-Thought 很强,但它有一个天然问题: 模型的“思考”完全发生在内部表示里,不和外部世界交互。
这会导致两个经典问题:
第一,知识过期或缺失时,推理会建立在错误事实之上。 第二,一旦中间某一步想错,后面会沿着错误链条继续滚下去。
论文中明确指出,CoT 虽然能形成推理链,但这种推理是一个“静态黑箱”,没有被外部世界校正,因此容易产生幻觉和错误传播。
你可以把它理解成:
用户问:A 和 B 谁先成立?
模型:
1. 我记得 A 是 1844
2. 我记得 B 是 1989
3. 所以 A 更早如果第 1 步记错了,后面整个链条都白搭。
2. 只会“做”的问题:执行没有高层控制
另一类系统会让模型直接输出动作,例如搜索、点击、导航、选择商品、操作环境。
这类方法的问题在于: 它们可能能“动起来”,但不知道为什么这么动,也不擅长动态规划。
论文里举了两个很典型的例子:
在问答任务里,Act-only 会搜索几个关键词,但可能不会整合结果,最后给出错误答案。 在 ALFWorld 这类环境里,Act-only 往往会重复做无效动作,比如不断尝试从错误位置拿一个并不存在的物体。
本质原因是:
- 没有显式的子目标分解
- 没有工作记忆
- 没有对异常情况的语言化调整
- 没有“我现在卡在哪里”的自我反馈
所以,只做不想,系统常常不是“不会做”,而是“做得很盲”。
二、ReAct 的核心思想:把语言本身加入动作空间
这篇论文最关键的一句话其实非常简单:
把 agent 的动作空间从 (A) 扩展为 (A \cup L),其中 (L) 是语言空间。 也就是说,模型除了可以执行外部动作,还可以生成语言形式的“thought”。
翻成工程语言,就是:
- Action:真的对外部环境产生影响,比如
search[...]、lookup[...]、click[...]、buy[...] - Thought:不会改变外部环境,但会更新内部上下文,帮助后续决策
这很重要,因为 Thought 虽然“不执行”,但它会改变后续行为。
比如:
Thought: 我需要先确认 Apple Remote 最初控制的是哪个软件
Action: search[Apple Remote]
Observation: ... originally designed to control Front Row ...
Thought: 现在需要查 Front Row 还可以被什么设备控制
Action: search[Front Row]
...这就不是“瞎搜”,而是 有目标的检索。论文第一页和第二页的示例图,已经很直观地展示了 Standard、CoT、Act-only、ReAct 四种方式的差异:ReAct 的轨迹里,思考和动作是交错出现的。
三、ReAct 不是“多写几句思维链”,而是改变了系统闭环
很多人第一次看 ReAct,会误以为它只是“CoT + Tool Use”。
这理解不够准确。
真正的区别在于,ReAct 不是先完整思考、再执行,而是把推理和执行做成了一个闭环:
context_t
↓
Thought_t
↓
Action_t
↓
Observation_t
↓
Thought_(t+1)论文里指出,Thought 可以承担很多不同角色,例如:
- 分解任务目标
- 制定行动计划
- 从 observation 里抽取关键事实
- 追踪当前进度
- 根据异常调整策略
- 注入常识
- 重新表述检索查询
这一点非常像人在做复杂任务时的状态机:
先想:我要先找杯子
再做:去厨房
再看:厨房没有
再想:杯子更可能在餐桌或洗碗机旁
再做:去餐桌所以 ReAct 的价值,不只是“增强推理”,而是 让推理参与控制。
四、ReAct 在不同任务里的样子并不一样
这篇论文还有一个很值得工程上借鉴的点: Thought 的密度不是固定的,而是任务相关的。
1. 在知识密集型任务里:Thought 要密
在 HotPotQA 和 FEVER 这类任务上,论文采用的是 dense thought,也就是几乎每一步动作前后都伴随推理。因为这里核心难点就是:
- 该搜什么
- 搜到的信息说明了什么
- 还缺哪一跳
- 最后如何综合答案
所以这类任务的轨迹更像:
Thought
Action
Observation
Thought
Action
Observation
...
Finish论文对这部分做了明确说明。
2. 在决策任务里:Thought 要稀疏
而在 ALFWorld、WebShop 这种长时程交互任务里,如果你每一步都写 thought,反而会很累赘。
所以论文采取的是 sparse thought:
- 只在关键决策点思考
- 大部分基础动作直接执行
- 当遇到子目标切换、环境变化、探索策略调整时再插入 thought
这非常符合真实工程。因为长链路 Agent 如果每一步都 verbose reasoning,会带来三个问题:
- token 开销很大
- 推理过密会拖慢执行
- 很多动作其实不需要显式思考
论文在 ALFWorld 中把 sparse thoughts 设计为四类: 分解目标、追踪子目标完成情况、决定下一子目标、基于常识判断物体可能位置。
这点很值得现在做 Agent 的工程团队借鉴: 不是所有任务都需要“满屏思维链”,关键是把 thought 放在高价值节点。
五、方法细节:知识任务里的 ReAct 是怎么设计的?
先看论文里最清晰的一部分:问答和事实验证。
作者设计了一个非常简单的 Wikipedia API,只有三种动作:
search[entity]:查一个实体页面,返回前 5 句,若无则给相似实体lookup[string]:在当前页面里像 Ctrl+F 一样找包含该字符串的下一句finish[answer]:提交最终答案
这个设计其实挺妙。因为它不是一个很强的 Retriever,反而故意比较弱。论文明确说,它比 SOTA 检索器弱得多,目的就是模拟人怎么查 Wikipedia,并迫使模型通过显式语言推理来决定检索行为。
也就是说,重点不是“给模型一个万能搜索器”,而是让模型学会:
- 先找哪个实体
- 没找到怎么办
- 是否需要 reformulate query
- 什么时候已经足够回答
一个最小版 ReAct QA 伪代码
下面这段代码不是论文原代码,而是把它的思想抽成一个你能立刻看懂的版本:
from typing import Callable, List, Dict
class ReActQAAgent:
def __init__(self, llm: Callable[[str], str], wiki_api):
self.llm = llm
self.wiki_api = wiki_api
def build_prompt(self, question: str, trajectory: List[Dict[str, str]]) -> str:
lines = [
"You are an agent that solves QA by interleaving Thought, Action, Observation.",
f"Question: {question}"
]
for step in trajectory:
if "thought" in step:
lines.append(f"Thought: {step['thought']}")
if "action" in step:
lines.append(f"Action: {step['action']}")
if "observation" in step:
lines.append(f"Observation: {step['observation']}")
lines.append("Thought:")
return "\n".join(lines)
def act(self, action: str) -> str:
if action.startswith("search[") and action.endswith("]"):
entity = action[len("search["):-1]
return self.wiki_api.search(entity)
if action.startswith("lookup[") and action.endswith("]"):
keyword = action[len("lookup["):-1]
return self.wiki_api.lookup(keyword)
if action.startswith("finish[") and action.endswith("]"):
answer = action[len("finish["):-1]
return f"FINAL_ANSWER::{answer}"
return "Invalid action"
def run(self, question: str, max_steps: int = 7) -> str:
trajectory = []
for _ in range(max_steps):
prompt = self.build_prompt(question, trajectory)
output = self.llm(prompt)
# 假设模型输出两行:
# Thought: ...
# Action: ...
thought = ""
action = ""
for line in output.splitlines():
if line.startswith("Thought:"):
thought = line[len("Thought:"):].strip()
elif line.startswith("Action:"):
action = line[len("Action:"):].strip()
trajectory.append({"thought": thought, "action": action})
obs = self.act(action)
if obs.startswith("FINAL_ANSWER::"):
return obs.replace("FINAL_ANSWER::", "")
trajectory.append({"observation": obs})
return "No answer"这段代码对应了论文里的哪些思想?
第一,它把 thought 作为上下文状态更新,不是摆设。 第二,它把外部环境返回的 observation 接回 prompt,形成闭环。 第三,它限制最大步数,这和论文里对 HotpotQA / FEVER 设置 step budget 的思路一致:如果 ReAct 在限定步数内还没答出来,就说明当前轨迹可能不靠谱。
六、为什么 ReAct 能减少幻觉?
这是整篇论文最值得反复讨论的点。
论文在 HotpotQA 上对 ReAct 和 CoT 的成功/失败模式做了人工分析。结果很有意思:
- CoT 的主要问题之一是 hallucination
- ReAct 的轨迹更 grounded、更 fact-driven
- CoT 的 major failure mode 里,幻觉占比很高,而 ReAct 在这方面明显更低
原因并不神秘。
1. CoT 的事实来自“记忆”
它是这样工作的:
Thought 1: 我记得 X...
Thought 2: 所以 Y...
Answer: Z这里每一步都依赖模型内部知识。
2. ReAct 的事实来自“观察”
它是这样工作的:
Thought: 我需要确认 X
Action: search[X]
Observation: 页面返回...
Thought: 从结果看,X 不是 Y
Action: lookup[...]
Observation: ...
Answer: Z这意味着:
- 推理不再完全依赖参数记忆
- 中间事实可以被外部信息校验
- 轨迹可诊断
- 错误更容易定位
这对工程系统特别重要。因为生产环境中,你最怕的不是模型答错,而是 答错了你还不知道错在哪一步。ReAct 给你的不是一个答案,而是一串可检查轨迹。
七、但 ReAct 不是完美的,它也有代价
如果你只看“ReAct 很强”,会误读这篇论文。作者其实很诚实地分析了它的问题。
在 HotpotQA 上,ReAct 并没有完全压制 CoT。事实上:
- ReAct 在 FEVER 上优于 CoT
- 但在 HotpotQA 上略低于 CoT
- 两者结合效果反而更好
这说明一个关键现实:
“更 grounded” 不等于“永远更准”。
为什么?
1. ReAct 的结构更强约束,灵活性反而下降
论文指出,ReAct 虽然更可信,但由于必须在 thought / action / observation 之间交替,推理结构受到了约束,因此在灵活构造复杂 reasoning chain 时,可能不如 CoT 自由。
2. 检索质量会直接影响推理质量
作者还专门提到,ReAct 很依赖搜索是否有信息量。 如果搜索结果为空、歧义大、或者不含关键证据,后续 reasoning 会被带偏。论文统计里,search result error 也是 ReAct 的重要失败来源。
3. 它可能会陷入循环
论文观察到一种 ReAct 特有错误: 模型反复生成前面已经出现过的 thought 和 action,跳不出局部循环。作者猜测这可能和 greedy decoding 有关。
这在今天的 Agent 系统里仍然是高频问题。很多人把它叫做:
- loop
- dead-end retry
- self-repetition
- stuck state
所以你会发现,ReAct 论文其实已经预示了后来 Agent Engineering 里一大堆问题。
八、论文最有启发的一点:ReAct + CoT-SC 往往比单用更好
论文没有停留在“ReAct 替代 CoT”,而是提出了两种组合方式:
-
ReAct → CoT-SC 如果 ReAct 在限定步数内没答出来,就回退到 CoT-SC
-
CoT-SC → ReAct 如果 CoT-SC 的多数票不够稳定,说明内部知识不自信,就回退到 ReAct 去查外部信息
这个思想非常工程化。
因为现实里根本没有必要坚持一种模式打天下。 更好的方式往往是:
- 能靠内部知识搞定的,就别查外部
- 内部知识不可靠时,再去调用工具
- 工具调用卡住时,再换另一条路
这本质上是一个 controller / fallback policy。
一个很实用的混合式控制器示例
def answer_with_hybrid(question: str, cot_sc_solver, react_solver):
cot_answers = cot_sc_solver.sample(question, n=5)
majority_answer, majority_count = cot_sc_solver.majority_vote(cot_answers)
# 如果多数票不稳,说明模型“想得不自信”
if majority_count < 3:
return react_solver.run(question)
return majority_answer或者反过来:
def answer_with_react_fallback(question: str, react_solver, cot_sc_solver):
answer = react_solver.run(question, max_steps=7)
if answer == "No answer":
return cot_sc_solver.solve(question)
return answer这两段代码都非常符合论文提出的 heuristics。
今天很多 RAG Agent、Web Agent、Research Agent,本质上也都是这个思路:
- 先 internal solve
- 不行再 external solve
- 还不行再回退 / 重试 / 改写 query
九、决策任务里,ReAct 真正证明了“思考不是装饰品”
论文后半部分讨论 ALFWorld 和 WebShop,这部分非常关键,因为它证明 ReAct 不是只对 QA 有用,而是对 决策型 Agent 也有价值。
1. 在 ALFWorld 上,ReAct 明显优于 Act-only
论文报告:
- ReAct 在 ALFWorld 上的 best trial 平均成功率是 71%
- Act-only 的 best of 6 是 45%
- BUTLER 是 37% 而且 ReAct 的优势在多个任务类型上都比较稳定。
为什么会这样?
因为在环境任务里,单纯动作预测经常会失败在三个地方:
- 不会分解高层目标
- 不会追踪子目标是否完成
- 不会利用常识缩小搜索空间
比如“找台灯下的纸”,一个没有 thought 的 agent 可能就是乱走、乱看。 而有 thought 的 agent 会更像:
Thought: 目标是把 paper 放到 desklamp 下
Thought: 首先需要找到 paper,paper 可能在 desk / table / shelf 附近
Action: go to desk1
Observation: ...
Thought: 这里没有,下一步查 shelf你会发现,所谓“推理提升决策”,本质上是让 agent 拥有了一个轻量的高层 planner。
2. 在 WebShop 上,ReAct 说明“搜索不只是搜到结果,还要判断结果”
WebShop 是一个很真实的环境:
- 商品标题 noisy
- 属性多
- 说明文本长
- 用户需求包含多个约束
- action 包括搜索、选商品、选属性、下单
论文结果显示:
- Act: Score 62.3 / SR 30.1
- ReAct: Score 66.6 / SR 40.0 也就是说,成功率绝对提升了 10%。
这个结果很有代表性,因为 WebShop 非常接近现实中的搜索型 Agent:
- 用户需求是自然语言
- 检索结果不干净
- 需要进行属性约束匹配
- 需要权衡“继续搜”还是“可以买了”
论文指出,ReAct 能更好识别 instruction relevant 的商品与选项,因为 reasoning 能帮助它桥接 noisy observation 和 action。
这件事今天依然成立。 很多电商 Agent、表单填写 Agent、浏览器 Agent 的提升,不是来自“更多点击”,而是来自 在关键位置插入判断。
十、ReAct 和 Inner Monologue 的区别:不是把环境回显一遍就叫 reasoning
论文还做了一个很有意思的对比:ReAct vs ReAct-IM。
Inner Monologue 类方法的“思考”,很多时候只是把环境状态再描述一遍,比如:
我已经拿到了杯子
我还需要找到桌子这类文本当然有帮助,但它更像 状态回显,不是真正的高层 reasoning。
论文专门指出,ReAct 的 thought 是灵活且稀疏的,可以包含多种 reasoning 类型;而 IM 风格主要是围绕环境反馈做密集描述。实验中 ReAct 在 ALFWorld 上也明显优于这种 IM-style prompting。
这对今天的 Agent 设计也很重要:
不是你把 observation 再说一遍,系统就变聪明了。 真正有价值的 thought,必须改变后续决策。
判断一个 thought 有没有价值,可以问自己一句:
“如果删掉这句 thought,后续 action 会不会变差?”
如果不会,那它大概率只是 verbose,不是 reasoning。
十一、工程上如何落地 ReAct:我建议你重点做这 5 件事
如果你现在在做 research agent、web agent、materials science agent,ReAct 不是一篇只看不做的论文。它真正能落到系统设计里。
1. 明确区分三类消息:Thought / Action / Observation
你的 agent trace 最好天然支持这三类节点:
from dataclasses import dataclass
@dataclass
class Thought:
content: str
@dataclass
class Action:
tool_name: str
tool_input: str
@dataclass
class Observation:
content: str不要把所有东西都塞进一个字符串里。 因为后面你要做:
- 日志审计
- 可视化 trace
- 错误分析
- thought masking
- action replay
如果不结构化,后面全是坑。
2. 只在高价值节点生成 thought
别让模型每一步都输出 thought。
一个比较合理的策略是:
- 新子目标开始时
- 任务失败或观测异常时
- 多工具候选需要决策时
- 结束前做 final synthesis 时
触发 thought。
例如:
def need_thought(state) -> bool:
return (
state.new_subgoal
or state.last_action_failed
or state.has_multiple_tool_options
or state.ready_to_finish
)这其实就是把论文里的 sparse reasoning 工程化。
3. 给 action 留足约束,不要让 thought 代替 schema
Thought 可以自由,但 Action 最好强约束。
ALLOWED_ACTIONS = {
"search": ["query"],
"lookup": ["keyword"],
"finish": ["answer"]
}然后让模型输出 JSON:
{
"thought": "我需要先确认 Front Row 是什么",
"action": {
"name": "search",
"args": {
"query": "Front Row software"
}
}
}为什么?
因为真正生产中,Thought 出错还好,Action 出错往往会:
- 调错 API
- 重复调用
- 打爆速率限制
- 触发危险操作
所以 语言自由度要留给 thought,动作必须结构化。
4. 给 ReAct 增加 loop breaker
论文已经发现 ReAct 会重复 thought/action。 所以你在工程里最好默认加一个 loop 检测器:
def detect_loop(history, k=3):
recent = history[-k:]
signatures = [(x.get("thought", ""), x.get("action", "")) for x in recent if isinstance(x, dict)]
return len(signatures) == k and len(set(signatures)) == 1一旦检测到循环:
- 强制重写 query
- 强制切换工具
- 强制进入“反思模式”
- 或直接 fallback 到另一个 solver
例如:
if detect_loop(trajectory):
trajectory.append({
"thought": "我似乎在重复之前的步骤。需要换一个查询角度或改用其他策略。"
})5. 把 ReAct 当成“控制器”,不是“答案生成器”
这是我最想强调的。
ReAct 的真正价值不只是最后 answer 对不对,而是它提供了一套 过程控制接口:
- thought 是可编辑的
- action 是可约束的
- observation 是可审计的
- 整个 trace 是可回放的
所以你可以在中间插入:
- 人类反馈
- 规则引擎
- 风险控制
- 预算控制
- 工具白名单
- 记忆系统
论文也特别强调 ReAct 的 interpretability、controllability、diagnosability。
这对实际系统太重要了,因为企业不会只关心“答对没”,还关心:
- 为什么这么做
- 错在哪一步
- 能不能中断
- 能不能重放
- 能不能审计
十二、一个更接近真实项目的 ReAct Agent 骨架
下面这段我给你写一个更像真实工程的简化版骨架。
from typing import List, Dict, Any, Optional
class ToolExecutor:
def __init__(self, tools: Dict[str, Any]):
self.tools = tools
def run(self, name: str, args: Dict[str, Any]) -> str:
if name not in self.tools:
return f"ToolError: unknown tool {name}"
try:
return self.tools[name](**args)
except Exception as e:
return f"ToolError: {e}"
class ReActAgent:
def __init__(self, llm, tool_executor: ToolExecutor, max_steps: int = 8):
self.llm = llm
self.tool_executor = tool_executor
self.max_steps = max_steps
def build_messages(self, task: str, trace: List[Dict[str, Any]]) -> List[Dict[str, str]]:
system = {
"role": "system",
"content": (
"You are a ReAct-style agent.\n"
"At each step, think briefly, then choose exactly one action.\n"
"Use observations to update your plan.\n"
"Return JSON with keys: thought, action_name, action_args."
)
}
content = [f"Task: {task}"]
for step in trace:
if step["type"] == "thought":
content.append(f"Thought: {step['content']}")
elif step["type"] == "action":
content.append(f"Action: {step['name']}({step['args']})")
elif step["type"] == "observation":
content.append(f"Observation: {step['content']}")
user = {"role": "user", "content": "\n".join(content)}
return [system, user]
def parse_output(self, text: str) -> Dict[str, Any]:
# 真实工程中建议严格 JSON schema 校验
import json
return json.loads(text)
def detect_repetition(self, trace: List[Dict[str, Any]]) -> bool:
actions = [x for x in trace if x["type"] == "action"]
if len(actions) < 3:
return False
last_three = actions[-3:]
sig = [(a["name"], str(a["args"])) for a in last_three]
return len(set(sig)) == 1
def solve(self, task: str) -> str:
trace: List[Dict[str, Any]] = []
for step_id in range(self.max_steps):
if self.detect_repetition(trace):
trace.append({
"type": "thought",
"content": "我似乎在重复相同动作,下一步需要改变策略。"
})
messages = self.build_messages(task, trace)
raw = self.llm(messages)
obj = self.parse_output(raw)
trace.append({"type": "thought", "content": obj["thought"]})
trace.append({
"type": "action",
"name": obj["action_name"],
"args": obj["action_args"]
})
if obj["action_name"] == "finish":
return obj["action_args"]["answer"]
obs = self.tool_executor.run(obj["action_name"], obj["action_args"])
trace.append({"type": "observation", "content": obs})
return "FAILED"这段骨架已经体现了很多 ReAct 的核心工程点:
- Thought / Action / Observation 显式分离
- 外部工具返回 observation
- trace 可审计
- 重复动作可检测
- finish 是一个显式终止动作
如果你后面要把它接 LangGraph、LangChain、OpenAI tools、浏览器控制器,其实就是在这个骨架上不断加模块。
十三、这篇论文最值得带走的 6 个认知
最后我不只总结观点,而是总结成你以后做系统时能反复用的认知。
认知 1:推理不是为了“解释答案”,而是为了“控制行为”
这是 ReAct 最重要的思想升级。 Thought 不只是可解释性产物,它是控制信号。
认知 2:工具调用不是越多越好,关键是有没有 reasoning 引导
不会思考的 tool use,很多时候只是随机操作。
认知 3:grounding 能降低 hallucination,但会引入检索与控制成本
所以不能迷信“接了搜索就完美”。
认知 4:不同任务需要不同密度的 thought
知识任务 dense thought,长链路决策任务 sparse thought。
认知 5:最强系统往往不是单一范式,而是可切换的混合控制器
ReAct + CoT-SC 的结果已经说明了这一点。
认知 6:真正可落地的 Agent,必须可审计、可中断、可重放
这也是 ReAct 比“黑箱直接回答”更适合工程系统的原因。
结语
ReAct 这篇论文真正厉害的地方,不只是提出了一个 prompt 格式,而是它提前把后面两三年 Agent Engineering 的很多核心问题都点出来了:
- 什么时候该想,什么时候该做
- 怎么把外部 observation 接回推理
- 如何降低 hallucination
- 如何处理长链路任务
- 如何让 agent 过程可诊断、可控制
- 如何在内部知识与外部工具之间做切换
所以如果你今天在做 research agent、materials science agent、web agent,ReAct 不是“经典论文看看就好”,而是一篇非常值得落实到架构设计里的论文。
它告诉我们的不是“大模型要会思考”,而是:
强系统的关键,不在于一直思考,也不在于一直行动,而在于把思考和行动编织成一个闭环。