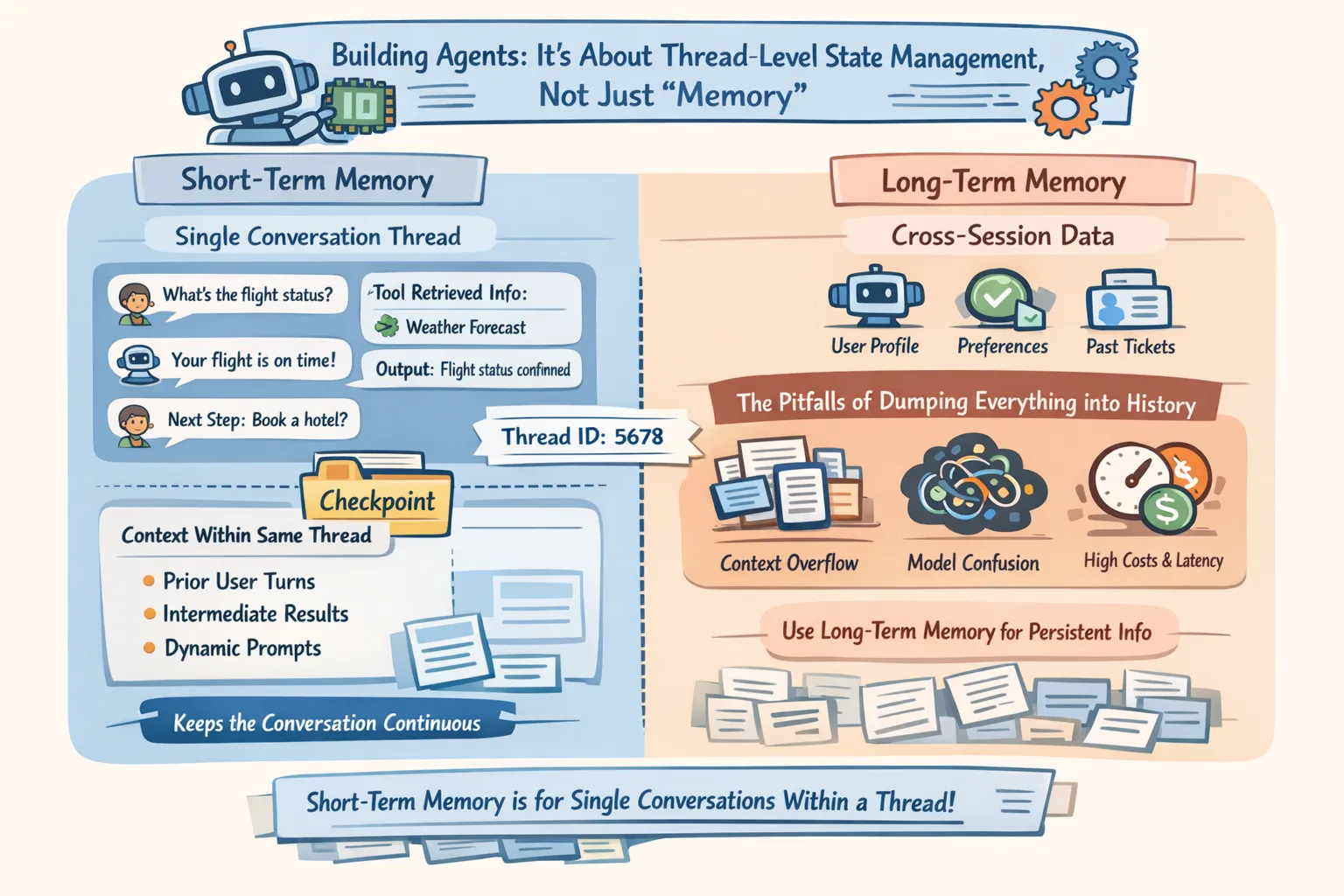
官方文档明确把 short-term memory 定义为单个 thread / conversation 内的记忆。线程相当于一条会话链路:同一个 thread_id 下,多轮交互共享上下文;不同 thread_id 之间彼此隔离。它解决的是“这一场对话如何连续”,不是“跨会话长期记住用户画像”。跨线程、跨 session 的持久化记忆,应使用 long-term memory。(LangChain Docs)
这一区分在生产里非常重要。很多团队一开始把“用户昵称、权限、偏好、上次工单状态、工具查询结果”全都塞进消息历史,结果很快遇到三个问题:上下文窗口爆掉、模型开始被陈旧内容干扰、调用成本和延迟一起上升。官方文档也点明了这一点:即使模型支持长上下文,长历史仍会导致性能下降、响应变慢、成本增加。(LangChain Docs)
一、先别谈“记忆”,先把线程状态接起来
LangChain 的接入方式非常直接:创建 agent 时传入 checkpointer。短期记忆会作为 agent state 的一部分保存;每次 agent invoke,或者某一步(例如 tool call)完成后,状态都会更新;每一步开始时又会从状态中读取。也就是说,短期记忆的读写粒度不是“整轮对话结束”,而是图执行过程中的 step 级别。这对工具链 Agent 很关键,因为很多中间结果并不是最终回答,但下一步必须用到。(LangChain Docs)
最小接入示例可以写成这样:
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
def get_user_info():
return "ok"
agent = create_agent(
"gpt-5",
tools=[get_user_info],
checkpointer=InMemorySaver(),
)
config = {"configurable": {"thread_id": "user-42-session-001"}}
agent.invoke(
{"messages": [{"role": "user", "content": "你好,我叫 Bob"}]},
config,
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "我刚才说我叫什么?"}]},
config,
)
print(result["messages"][-1].content)这里最重要的不是 InMemorySaver(),而是 thread_id。没有 thread_id,你就没有会话隔离;thread_id 设计得不好,短期记忆就会串会话。工程上通常不要直接用裸用户 ID,而是用 user_id + conversation_id 或 tenant_id + user_id + session_id 这样的复合键,避免用户开多个窗口时上下文互相污染。这个复合键设计属于工程扩展,但和官方 thread 机制是完全一致的落地方向。官方示例同样通过 configurable.thread_id 绑定线程。(LangChain Docs)
二、开发环境能用 InMemory,生产环境别偷懒
官方文档把 InMemorySaver 放在入门示例里,但在生产章节明确建议:使用数据库支撑的 checkpointer,示例给的是 PostgresSaver,并支持自动建表。(LangChain Docs)
官方示例大致如下:
from langchain.agents import create_agent
from langgraph.checkpoint.postgres import PostgresSaver
DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup()
agent = create_agent(
"gpt-5",
tools=[],
checkpointer=checkpointer,
)这个设计背后的工程含义很明确:
-
进程重启后记忆不能丢
InMemorySaver只适合本地调试。服务一重启,线程历史全没了。 -
多副本部署必须共享状态
Kubernetes 下同一个用户第二轮请求未必落到同一个 Pod,状态必须落数据库。
-
状态写入要可观测、可恢复
线上排查“为什么模型忘了用户刚说的话”时,如果没有可查的 checkpoint,很难定位到底是 thread_id 错了、写状态失败了,还是中间 middleware 把消息删了。
官方还提到除了 Postgres,还有 SQLite、Azure Cosmos DB 等 checkpointer 选项;从生产经验看,优先级通常是:本地 SQLite,测试/灰度 Postgres,云上再按基础设施选托管数据库。(LangChain Docs)
三、默认只记 messages,但工程里你往往不止要记消息
官方默认使用 AgentState 管理短期记忆,其中最核心的是 messages 字段,也就是消息历史。与此同时,文档也明确支持你继承 AgentState,扩展出自己的状态字段,再通过 state_schema 传给 create_agent。(LangChain Docs)
官方示例:
from langchain.agents import create_agent, AgentState
from langgraph.checkpoint.memory import InMemorySaver
class CustomAgentState(AgentState):
user_id: str
preferences: dict
agent = create_agent(
"gpt-5",
tools=[],
state_schema=CustomAgentState,
checkpointer=InMemorySaver(),
)
result = agent.invoke(
{
"messages": [{"role": "user", "content": "Hello"}],
"user_id": "user_123",
"preferences": {"theme": "dark"}
},
{"configurable": {"thread_id": "1"}}
)这段代码真正有价值的地方在于:你终于可以把“消息历史”与“业务状态”分开存。
在实际项目里,我建议至少把下面两类信息从纯消息文本里剥离出来:
- 业务强约束字段:
user_id、tenant_id、order_id、ticket_id - 可复用执行上下文:
preferences、selected_product、retrieval_cache_key、tool_results_summary
原因很简单:消息历史是给模型看的,业务状态是给系统和工具链看的。把所有东西都塞进自然语言消息里,会出现两个典型问题:第一,工具难以稳定解析;第二,模型容易“看见了但没用对”。把关键字段升级为显式状态,系统更稳。这个“扩展状态 schema”能力,是官方 short-term memory 设计里最适合工程化的一部分。(LangChain Docs)
四、长对话迟早会炸,上线前就要选好裁剪策略
官方把长对话下的常见处理方式总结成四类:trim messages、delete messages、summarize messages、自定义策略。核心目标只有一个:不要让历史无限增长到拖垮模型上下文。(LangChain Docs)
这四种策略不要混着谈,它们在工程上分别对应不同场景。
1)Trim:最便宜,适合客服问答、简单 Copilot
官方建议可以在接近上下文上限时,根据 token 或条数裁剪消息,并用 @before_model middleware 在模型调用前执行。示例里保留首条消息和最近几条消息,通过 RemoveMessage(id=REMOVE_ALL_MESSAGES) 先清空,再回填保留部分。(LangChain Docs)
简化后的思路如下:
from langchain.messages import RemoveMessage
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langchain.agents.middleware import before_model
from langchain.agents import AgentState
@before_model
def trim_messages(state: AgentState, runtime):
messages = state["messages"]
if len(messages) <= 6:
return None
first_msg = messages[0]
recent_messages = messages[-5:]
return {
"messages": [
RemoveMessage(id=REMOVE_ALL_MESSAGES),
first_msg,
*recent_messages,
]
}为什么要保留第一条?因为第一条通常是最早的任务目标或核心约束,比如“帮我写一封英文道歉邮件”“这个线程是在排查订单 12345”。而最近几条则保留局部连续性。官方示例里也体现了类似思路:保留首条和最近消息后,模型仍能回答“你叫 Bob”。(LangChain Docs)
工程上,Trim 适合以下场景:
- 问答轮次多,但每轮依赖近邻上下文
- 每轮任务基本独立,不太依赖很久以前的细节
- 对成本敏感,希望少引入额外 summarization 模型
它的缺点也很明显:删掉就真没了。你可能恰好把用户早先给出的关键约束裁没。
2)Delete:不是“裁给模型看”,而是“从状态里永久删除”
官方把 Delete 单独列出来,是因为它和 Trim 不是一回事。Trim 通常是“调用前整理上下文”;Delete 则是直接修改 LangGraph state,把某些消息永久移除。示例里演示了删除最早两条消息,或者用 REMOVE_ALL_MESSAGES 清空全部消息。(LangChain Docs)
这在工程里有两个高频用途:
- 隐私合规:工具返回了不该长期留存的内容,生成后立刻删
- 中间噪声清理:某些工具调用过程特别长,日志式消息不应该一直挂在历史里
但官方特别提醒了一个很容易踩坑的点:删完后,消息历史仍必须满足模型提供方的格式要求。比如有些 provider 要求历史以 user 开头;多数 provider 要求带 tool call 的 assistant 消息后面必须跟对应的 tool 结果。你不能随便删出一个“残缺对话树”。(LangChain Docs)
这条非常关键。很多 Agent 线上报错,不是模型能力问题,而是消息历史被 middleware 删坏了。
3)Summarize:成本更高,但最接近“既压缩又保真”
官方指出,简单 trim 或 remove 的问题是会丢信息,因此提供了内置 SummarizationMiddleware。它可以在消息过长时,用另一个模型把前文总结成摘要,并保留最近若干条消息。示例中主模型用 gpt-4.1,总结模型用 gpt-4.1-mini,在 token 达到 4000 时触发,保留最近 20 条消息。(LangChain Docs)
官方示例:
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
from langgraph.checkpoint.memory import InMemorySaver
agent = create_agent(
model="gpt-4.1",
tools=[],
middleware=[
SummarizationMiddleware(
model="gpt-4.1-mini",
trigger=("tokens", 4000),
keep=("messages", 20)
)
],
checkpointer=InMemorySaver(),
)这套机制更适合复杂 Agent,例如:
- 多轮需求澄清后再写代码/方案
- 需要长期追踪变量、角色、约束的任务型对话
- 工具调用很多,但旧内容仍有保留价值
不过从工程角度要补一句:summary 不是免费午餐。你相当于把“上下文管理”变成了一次额外模型调用。收益是保住关键信息,代价是成本、时延,以及摘要本身可能引入信息漂移。因此我通常建议:
- 短流程 Agent:优先 Trim
- 中流程、结构化任务:Trim + 关键字段进 state
- 长流程、高信息密度:Summarize + state 显式字段
这也是官方模式背后比较合理的实践路径。(LangChain Docs)
五、真正好用的短期记忆,不只给模型看,还要给工具看
官方文档专门有一节讲“Access memory”,这是整篇最有工程价值的部分之一。短期记忆不只是消息列表,它本质上是 state,而 state 可以在工具和 middleware 中直接读取、修改。(LangChain Docs)
1)工具读取状态:别再让模型反复复述业务参数
官方给出的方式是:工具函数通过 runtime: ToolRuntime 访问 runtime.state。这个参数不会暴露在工具签名给模型看,但工具内部可以直接拿到状态。(LangChain Docs)
官方示例是按 user_id 查用户信息:
from langchain.agents import create_agent, AgentState
from langchain.tools import tool, ToolRuntime
class CustomState(AgentState):
user_id: str
@tool
def get_user_info(runtime: ToolRuntime) -> str:
user_id = runtime.state["user_id"]
return "User is John Smith" if user_id == "user_123" else "Unknown user"这意味着什么?意味着你不用每次都让模型从消息里“理解”当前用户是谁。对订单查询、CRM、工单、权限判断这类业务来说,这非常实用。你把 user_id 放进 state,工具直接读,不靠模型做语义推理,稳定性会高很多。(LangChain Docs)
2)工具写状态:把中间结果升级成后续可复用上下文
官方还演示了工具返回 Command(update=...) 来更新状态。示例里第一个工具 update_user_info 查询用户姓名后,把 user_name 写回 state,同时写入一条 ToolMessage;第二个工具 greet 再从 state 中读取 user_name 完成问候。(LangChain Docs)
这个模式在线上很有用,因为很多工具调用不是“一次性消费”的。比如:
- 检索工具查到了候选文档 ID,后面排序工具还要用
- SQL 工具拿到了订单主键,后面详情工具还要接着查
- OCR 工具提取出发票号,后面校验工具要复用
如果这些结果只保留在消息文本里,后续步骤要么靠模型复述,要么再次调用工具。前者不稳,后者浪费。把中间结果写回 short-term memory state,才是更像工程系统的做法。官方的 Command(update=...) 正是为这个设计的。(LangChain Docs)
六、短期记忆还能直接参与 Prompt 生成
官方除了工具读写状态,还给了另一个很实用的用法:在 middleware 里利用状态动态生成 prompt。示例使用 @dynamic_prompt,从 runtime.context["user_name"] 中读取用户姓名,再生成 system prompt,让模型用这个名字称呼用户。(LangChain Docs)
这件事的工程意义是:不要把所有个性化都做成消息历史回放。一些稳定的、结构化的、强约束的信息,更适合直接编进动态 system prompt。例如:
- 当前租户品牌名
- 当前用户称呼
- 当前会话目标
- 当前输出风格要求
- 当前安全策略级别
比起“从历史里让模型自己悟出来”,显式注入 system prompt 更稳,也更省 token。官方示例已经说明这个能力是可直接接入的。(LangChain Docs)
七、before_model 和 after_model:一个管输入,一个管输出
官方文档把 short-term memory 的 middleware 接入点拆成了 @before_model 和 @after_model。前者用于模型调用前加工状态,后者用于模型调用后处理结果。前面提到的 Trim 就是典型 before_model;而 after_model 示例则演示了校验最后一条消息,如果包含敏感词就删除。(LangChain Docs)
这个设计很像传统后端里的请求/响应拦截器,工程上可以这样理解:
-
before_model:做上下文治理
例如裁剪消息、补齐动态 prompt、合并摘要、注入业务字段
-
after_model:做结果治理
例如审查敏感输出、清理不该落盘的信息、把最终结果写入状态摘要
如果要搭一个可维护的 Agent 服务,我建议把“记忆治理”明确拆到这两个阶段,而不是混在一堆 prompt 拼接逻辑里。官方实际上已经给出了这个演进路径。(LangChain Docs)
八、一个更像生产系统的设计建议
基于官方文档,我会把 short-term memory 设计成三层,而不是只有 messages:这是工程扩展建议,不是官方原文,但与官方 state/middleware/checkpointer 机制完全兼容。(LangChain Docs)
第 1 层:原始消息层
保留最近若干轮原始消息,主要服务模型当前推理。
第 2 层:结构化状态层
把业务强约束和工具中间结果存成显式字段,例如:
class ChatState(AgentState):
user_id: str
tenant_id: str
current_order_id: str | None = None
user_name: str | None = None
preferences: dict = {}
retrieved_doc_ids: list[str] = []第 3 层:摘要层
当历史过长时,用 summarization middleware 维护一份会话摘要,把老消息压缩掉。
这三层结合起来,通常比“只保留一大坨 messages”稳得多:
- 原始消息保证局部上下文
- 结构化状态保证工具和系统可控
- 摘要保证长链路不失忆
九、上线时最容易踩的五个坑
坑 1:thread_id 设计不当,导致串会话
同一个用户多开窗口,如果 thread_id 只用 user_id,短期记忆一定会串。官方机制要求按线程隔离;工程上必须用真正的会话粒度键。(LangChain Docs)
坑 2:删消息删坏了 tool 调用链
官方明确提醒:带 tool call 的 assistant message 后需要有对应 tool result。你删历史时如果只删了一半,很多 provider 会直接报错。(LangChain Docs)
坑 3:把数据库持久化当成“顺手一接”
checkpointer 一旦进生产,它就是关键链路。需要关注连接池、超时、失败重试、表结构迁移和观测。官方给了 Postgres 的基础接法,但线上还得补齐这些运维能力。(LangChain Docs)
坑 4:什么都放 messages,不做结构化状态
这样工具不得不从自然语言里“猜”参数,稳定性会越来越差。官方已经给了 state_schema、ToolRuntime、Command(update=...),就不要再把系统变量埋在对话文本里。(LangChain Docs)
坑 5:以为 summary 一定比 trim 好
不是。summary 增加额外调用,也可能把细节压缩错。官方只是提供能力,不代表默认最佳。实际选择要看任务长度、成本预算和信息密度。(LangChain Docs)
十、一个简化版的生产接入思路
最后给一个更像实战的接法,把官方几个能力拼起来:
from typing import Any
from pydantic import BaseModel
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import before_model, SummarizationMiddleware
from langchain.tools import tool, ToolRuntime
from langchain.messages import RemoveMessage, ToolMessage
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langgraph.types import Command
from langgraph.checkpoint.postgres import PostgresSaver
class AppState(AgentState):
user_id: str
user_name: str | None = None
preferences: dict = {}
class AppContext(BaseModel):
user_id: str
@tool
def load_user_profile(runtime: ToolRuntime[AppContext, AppState]) -> Command:
uid = runtime.context.user_id
name = "Bob" if uid == "user_123" else "Guest"
return Command(update={
"user_id": uid,
"user_name": name,
"messages": [
ToolMessage(
content="User profile loaded",
tool_call_id=runtime.tool_call_id
)
]
})
@before_model
def trim_messages(state: AppState, runtime) -> dict[str, Any] | None:
messages = state["messages"]
if len(messages) <= 12:
return None
return {
"messages": [
RemoveMessage(id=REMOVE_ALL_MESSAGES),
messages[0],
*messages[-10:]
]
}
DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup()
agent = create_agent(
model="gpt-5",
tools=[load_user_profile],
state_schema=AppState,
context_schema=AppContext,
middleware=[
trim_messages,
SummarizationMiddleware(
model="gpt-4.1-mini",
trigger=("tokens", 4000),
keep=("messages", 20),
),
],
checkpointer=checkpointer,
)
config = {"configurable": {"thread_id": "tenantA:user_123:conv_001"}}
result = agent.invoke(
{"messages": [{"role": "user", "content": "记住我叫 Bob,之后都这么称呼我"}]},
config,
context=AppContext(user_id="user_123")
)这段代码体现了一个比较合理的工程组合:
- 用
PostgresSaver做线程持久化 - 用
state_schema存结构化状态 - 用工具把用户信息写回状态
- 用
before_model做轻量裁剪 - 用
SummarizationMiddleware兜底长对话
这些能力都来自官方文档,只是按生产接法组合了一下。(LangChain Docs)
结语
LangChain 的 short-term memory 真正有价值的地方,不是“让模型更像人一样有记忆”,而是给 Agent 提供了一个线程级、可持久化、可读写、可治理的状态系统。官方文档表面上在讲 memory,实际上给的是一套更接近工程系统的方案:用 checkpointer 管持久化,用 state_schema 管结构化状态,用 middleware 管上下文治理,用 tool/runtime/command 让工具参与状态读写。(LangChain Docs)
如果只做 demo,你把消息历史塞进去就能跑;但如果真要上线,一个更靠谱的心智模型应该是:
Short-term memory = thread state + persistence + message governance + tool/state integration。
这才是它在工程里真正的落点。(LangChain Docs)