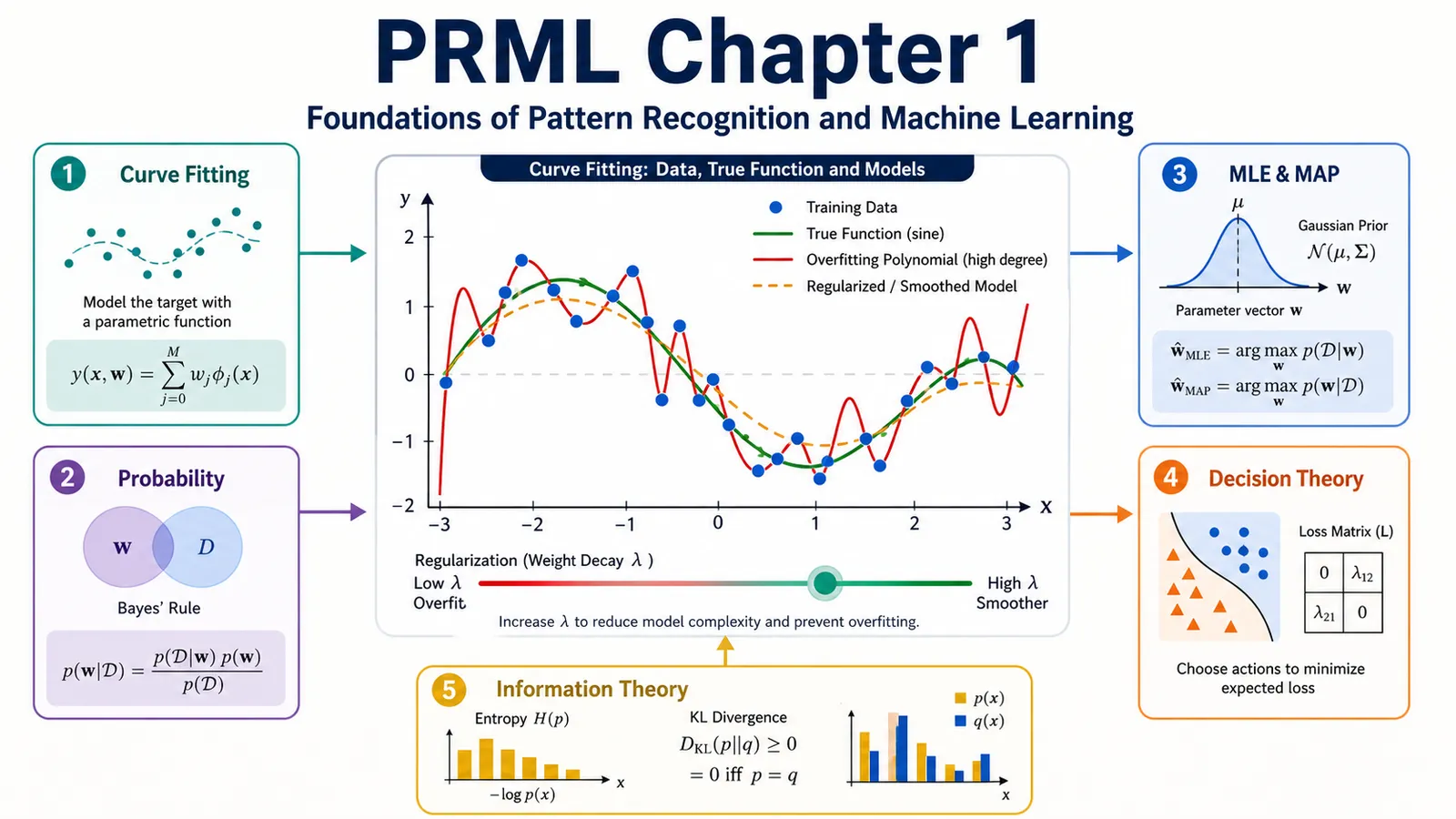
本文基于 Christopher Bishop 的《Pattern Recognition and Machine Learning》(2006)第一章,结合数学推导与 Python 代码,系统讲解机器学习的核心基础概念。
目录
- 引言:什么是模式识别
- 多项式曲线拟合
- 2.1 问题设定与最小二乘法
- 2.2 模型复杂度与过拟合
- 2.3 正则化:抑制过拟合
- 概率论基础
- 频率派 vs 贝叶斯派
- 高斯分布与 MLE 推导
- 5.1 一维高斯分布的 MLE
- 5.2 MLE 的偏差问题
- 5.3 多维高斯分布
- 曲线拟合的概率视角
- 6.1 最大似然与最小二乘的等价性
- 6.2 贝叶斯曲线拟合
- 模型选择
- 维度灾难
- 决策论
- 信息论
1. 引言:什么是模式识别
模式识别(Pattern Recognition)的目标是:从原始数据中自动发现规律,并利用这些规律对新数据做出决策或预测。
经典例子是手写数字识别(MNIST)。给定一张 28×28 像素的图像,我们希望机器能判断其表示的数字(0-9)。原始输入是 784 维的像素向量,而输出是 10 个类别之一。
输入空间:x ∈ ℝ^784(像素矩阵展平)
输出空间:y ∈ {0, 1, 2, ..., 9}
直接编写规则(if-else)来描述每个数字的形状是不现实的——数字的书写风格千变万化。机器学习的思路是:从训练数据中自动学习输入到输出的映射。
这里引出机器学习的三个核心问题:
| 问题类型 | 描述 | 例子 |
|---|---|---|
| 监督学习(Supervised) | 有标注数据,学习 x→y 的映射 | 分类、回归 |
| 无监督学习(Unsupervised) | 无标注数据,发现数据内在结构 | 聚类、密度估计 |
| 强化学习(Reinforcement) | 通过与环境交互获得奖励信号 | 游戏AI、机器人控制 |
2. 多项式曲线拟合
Bishop 用多项式曲线拟合作为贯穿全书的核心例子,直观呈现机器学习中的核心挑战。
2.1 问题设定与最小二乘法
问题设定:已知 个观测点 ,其中输入 ,目标值 , 为高斯噪声。目标是学习一个函数 来预测新的 对应的 。
模型: 阶多项式:
这是关于参数 的线性模型(尽管对 是非线性的)。线性模型具有良好的数学性质,可以求得解析解。
误差函数(平方误差):
前面的 是为了求导后消去系数,不影响最优解。几何意义:最小化每个训练点预测值与真实值之差的平方和(竖直方向误差)。
求解 :
令 为设计矩阵(Design Matrix),其中 :
则误差函数可以写成矩阵形式:
对 求导并令其为零:
这就是著名的正规方程(Normal Equation), 称为 的伪逆(Moore-Penrose Pseudoinverse)。
Python 实现:
import numpy as np
import matplotlib.pyplot as plt
def polynomial_features(x, degree):
"""构建多项式设计矩阵"""
return np.array([[xi**j for j in range(degree + 1)] for xi in x])
def fit_polynomial(x_train, t_train, degree):
"""用最小二乘法拟合多项式"""
Phi = polynomial_features(x_train, degree)
# 正规方程: w = (Phi^T Phi)^{-1} Phi^T t
w = np.linalg.lstsq(Phi, t_train, rcond=None)[0]
return w
def predict(x, w):
degree = len(w) - 1
Phi = polynomial_features(x, degree)
return Phi @ w
# 生成数据
np.random.seed(42)
N = 10
x_train = np.linspace(0, 1, N)
t_train = np.sin(2 * np.pi * x_train) + np.random.normal(0, 0.3, N)
x_test = np.linspace(0, 1, 200)
t_true = np.sin(2 * np.pi * x_test)
# 绘制不同阶数的拟合结果
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
for ax, M in zip(axes.flat, [0, 1, 3, 9]):
w = fit_polynomial(x_train, t_train, M)
y_pred = predict(x_test, w)
ax.scatter(x_train, t_train, color='blue', s=50, label='Training data')
ax.plot(x_test, t_true, 'g-', label='True: sin(2πx)')
ax.plot(x_test, y_pred, 'r-', label=f'M={M}')
ax.set_ylim(-1.5, 1.5)
ax.legend()
ax.set_title(f'Polynomial Degree M={M}')
plt.tight_layout()
plt.savefig('polynomial_fitting.png', dpi=150)
plt.show()2.2 模型复杂度与过拟合
Bishop 的实验( 个训练点)呈现了一个关键现象:
| 阶数 | 现象 | 训练误差 | 测试误差 |
|---|---|---|---|
| (常数) | 欠拟合,无法捕捉数据变化 | 大 | 大 |
| (线性) | 欠拟合,太简单 | 大 | 大 |
| 最优,良好泛化 | 小 | 小 | |
| 过拟合,完美通过每个训练点,但测试误差极大 | ≈0 | 极大 |
过拟合的本质: 的多项式有 10 个自由参数,恰好可以精确穿过 10 个训练点,但系数的量级极大(如 ),导致在训练点之间产生剧烈震荡。这是模型死记硬背了训练数据的噪声,而不是学习到了底层规律。
根均方误差(RMSE):
用 RMSE 而非总误差,是为了在不同大小数据集之间公平比较。
def rms_error(y_pred, y_true):
return np.sqrt(np.mean((y_pred - y_true)**2))
# 计算不同M的训练和测试误差
degrees = range(10)
train_errors, test_errors = [], []
x_test_pts = np.linspace(0, 1, 100)
t_test_pts = np.sin(2 * np.pi * x_test_pts) + np.random.normal(0, 0.3, 100)
for M in degrees:
w = fit_polynomial(x_train, t_train, M)
train_errors.append(rms_error(predict(x_train, w), t_train))
test_errors.append(rms_error(predict(x_test_pts, w), t_test_pts))
plt.figure(figsize=(8, 5))
plt.plot(degrees, train_errors, 'b-o', label='Training')
plt.plot(degrees, test_errors, 'r-o', label='Test')
plt.xlabel('Polynomial Degree M')
plt.ylabel('RMS Error')
plt.legend()
plt.title('Train vs Test Error vs Model Complexity')
plt.savefig('bias_variance.png', dpi=150)
plt.show()数据量与过拟合的关系:对于固定复杂度的模型,训练数据越多,过拟合越不严重。直觉上,数据越多,模型就越难"背下"每一个点。这引出一个重要观点:过拟合是一个关于相对于数据集大小而言模型复杂度过高的问题。
2.3 正则化:抑制过拟合
正则化通过在误差函数中加入惩罚项来约束参数的大小:
其中 , 是正则化系数,控制正则化的强度。
这种 L2 正则化在统计学中称为 Ridge Regression(岭回归),在神经网络中称为 Weight Decay(权重衰减)。
求解带正则化的正规方程:
注意 的加入保证了矩阵可逆(即使 奇异)。
正则化系数 的影响:
- :退化为无正则化,仍然过拟合
- 适中:系数被约束在合理范围,泛化性能好
- :所有系数趋向 0,模型退化为 ,欠拟合
def fit_polynomial_regularized(x_train, t_train, degree, lam):
"""带L2正则化的多项式拟合"""
Phi = polynomial_features(x_train, degree)
N, M_plus1 = Phi.shape
# (Phi^T Phi + lambda * I) w = Phi^T t
A = Phi.T @ Phi + lam * np.eye(M_plus1)
b = Phi.T @ t_train
w = np.linalg.solve(A, b)
return w
# 固定M=9,比较不同lambda
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
lambdas = [np.exp(-18), np.exp(-3), np.exp(0)]
labels = ['ln λ = -18 (适中)', 'ln λ = -3', 'ln λ = 0 (过强)']
for ax, lam, label in zip(axes, lambdas, labels):
w = fit_polynomial_regularized(x_train, t_train, 9, lam)
y_pred = predict(x_test, w)
ax.scatter(x_train, t_train, color='blue', s=50)
ax.plot(x_test, t_true, 'g-', label='True')
ax.plot(x_test, np.clip(y_pred, -1.5, 1.5), 'r-', label='Fitted')
ax.set_ylim(-1.5, 1.5)
ax.set_title(label)
ax.legend()
plt.suptitle('M=9 多项式正则化效果 (Regularization Effect)')
plt.tight_layout()
plt.show()关键洞察:正则化其实是在引入先验知识(系数不应太大)。从贝叶斯视角看, 对应于参数的高斯先验,这一点将在后面详细阐述。
3. 概率论基础
不确定性是模式识别的核心挑战,来源有二:
- 测量噪声:数据本身含有随机扰动
- 有限数据集:样本量有限,无法完全描述总体
概率论提供了一套一致性的框架来量化和操控不确定性。
3.1 概率的两大规则
Bishop 用一个直观的箱子水果例子引出概率的两条基本规则:
- 红箱:2 个苹果,6 个橙子;被选中概率 = 4/10
- 蓝箱:3 个苹果,1 个橙子;被选中概率 = 6/10
设 为选择的箱子, 为选到的水果。
联合概率(Joint Probability):
边缘化(Sum Rule / Marginalization):
物理含义:对不关心的变量 求和,得到 的边缘分布。
乘法规则(Product Rule):
其中 是条件概率,表示在已知 的条件下 的概率。
箱子例子的计算:
3.2 贝叶斯定理
从乘法规则出发,利用 :
整理得到贝叶斯定理(Bayes' Theorem):
其中:
- :先验概率(Prior)——在观测 之前对 的认识
- :似然(Likelihood)——在给定 时观测到 的概率
- :后验概率(Posterior)——在观测到 之后对 的更新认识
- :证据(Evidence),即归一化常数:
箱子例子反向推断:已知拿到橙子,问来自红箱的概率?
这是逆向推理的典型应用:虽然先验中红箱概率(4/10)小于蓝箱(6/10),但橙子更可能来自红箱(红箱 3/4 vs 蓝箱 1/4),所以后验概率反转为 2/3。
# 贝叶斯定理的Python验证
p_B_r = 0.4 # P(选红箱)
p_B_b = 0.6 # P(选蓝箱)
# 条件概率 P(水果|箱子)
p_orange_given_red = 3/4
p_orange_given_blue = 1/4
# 边缘概率 P(橙子) —— 全概率公式
p_orange = p_orange_given_red * p_B_r + p_orange_given_blue * p_B_b
print(f"P(橙子) = {p_orange:.4f}") # 9/20 = 0.45
# 贝叶斯定理
p_red_given_orange = p_orange_given_red * p_B_r / p_orange
print(f"P(红箱|橙子) = {p_red_given_orange:.4f}") # 2/3 ≈ 0.6667独立性:若 ,则 与 统计独立,此时 ,即知道 不提供关于 的任何信息。
3.3 连续概率密度
对于连续随机变量 ,若 落在区间 的概率为 (),则 称为概率密度函数(PDF, Probability Density Function)。
概率密度的性质:
注意: 本身不是概率,它可以大于 1(只要积分为 1)。
变量变换:若 ,则:
这说明概率密度不是简单代入变换的,需要乘以雅可比行列式。这也意味着概率密度的最大值点(众数)在非线性变换下会改变位置。
累积分布函数(CDF):,满足 。
连续情形的加法规则和乘法规则:
3.4 期望与协方差
期望(Expectation):
用有限样本近似期望:
条件期望:
方差(Variance):
协方差(Covariance):衡量两个变量的线性相关程度:
对于两个独立随机变量,(但反之不成立)。
协方差矩阵:对于随机向量 :
这是一个 对称正半定矩阵。
4. 频率派 vs 贝叶斯派
机器学习中最重要的哲学分歧之一,直接导致两类不同的算法体系。
符号约定:
- 数据:, 个样本,每个 维
- 参数:(待估计)
- 概率模型:,即 i.i.d. 假设
频率派(Frequentist)
核心观点:参数 是未知的固定常数,数据 是随机的。
方法:最大似然估计(MLE, Maximum Likelihood Estimation)
之所以取对数:① 数值稳定性(乘积变求和,避免下溢);② 数学上等价(对数是严格单调增函数)。
核心工具:最优化(Optimization)
MLE 导出的算法:线性回归(最小二乘)、逻辑回归、SVM、神经网络(标准形式)等。
贝叶斯派(Bayesian)
核心观点:参数 是随机变量,服从先验分布 。
贝叶斯定理应用:
- :先验(Prior)——观测数据前对参数的信念
- :似然(Likelihood)
- :后验(Posterior)——观测数据后的更新信念
- :归一化常数(边际似然/证据)
最大后验估计(MAP, Maximum A Posteriori):
MAP = MLE + 先验的约束(取对数后变加法)。
贝叶斯预测(Bayesian Prediction):
这是对所有可能的 进行加权平均(权重为后验概率),而不是只用一个点估计。
核心工具:积分(Integration)
由于分母 通常难以解析计算,需要近似方法:
- MCMC(马尔可夫链蒙特卡罗):采样近似积分
- 变分推断(Variational Inference):用简单分布近似后验
对比总结
| 特性 | 频率派 | 贝叶斯派 |
|---|---|---|
| 参数 | 固定常数 | 随机变量 |
| 核心操作 | 最优化 | 积分 |
| 数据的角色 | 随机变量 | 固定观测 |
| 不确定性表达 | 置信区间 | 后验分布 |
| 典型算法 | SVM, 标准神经网络 | 贝叶斯网络, GP, LDA |
| 先验的使用 | 无 | 核心要素 |
5. 高斯分布与 MLE 推导
高斯(正态)分布是机器学习中最重要的分布,其地位源于中心极限定理。
5.1 一维高斯分布的 MLE
一维高斯分布:
参数:均值 (分布中心),方差 (分布宽度)。
对数似然函数(对 个 i.i.d. 样本):
对 求偏导:
这就是样本均值,完全符合直觉。
对 求偏导(设 ):
这是样本方差。
5.2 MLE 的偏差问题
是 的无偏估计:
但 是 的有偏估计,推导如下:
关键步骤:,展开平方后:
MLE 系统性低估了方差!原因是:我们用 代替真实均值 ,而样本均值天然地比真实均值更"靠近"样本点,导致计算出的方差偏小。
无偏修正(贝塞尔校正):
分母用 而非 ,这也是 numpy.var(ddof=1) 和 pandas.std() 的默认行为。
import numpy as np
# 模拟MLE偏差
true_mu, true_sigma2 = 0.0, 1.0
np.random.seed(0)
n_datasets = 10000
N = 5 # 小数据集时偏差更明显
mle_means, mle_vars, corrected_vars = [], [], []
for _ in range(n_datasets):
data = np.random.normal(true_mu, np.sqrt(true_sigma2), N)
mu_mle = np.mean(data)
var_mle = np.var(data) # 除以N(有偏)
var_corr = np.var(data, ddof=1) # 除以N-1(无偏)
mle_means.append(mu_mle)
mle_vars.append(var_mle)
corrected_vars.append(var_corr)
print(f"真实均值: {true_mu:.4f}")
print(f"MLE均值期望: {np.mean(mle_means):.4f} (无偏)")
print(f"真实方差: {true_sigma2:.4f}")
print(f"MLE方差期望: {np.mean(mle_vars):.4f} (有偏, 约为 (N-1)/N * σ²)")
print(f"校正方差期望: {np.mean(corrected_vars):.4f} (无偏)")
print(f"理论有偏值: {(N-1)/N * true_sigma2:.4f}")这个偏差现象的深层含义:MLE 作为频率派的核心方法,在有限样本下会系统性地低估不确定性(方差)。这是过拟合问题的一个缩影——模型对训练数据的拟合"太好了"。贝叶斯方法通过引入先验,能够自动避免这种过估计。
5.3 多维高斯分布
多维高斯分布():
指数中的二次型 称为马氏距离(Mahalanobis Distance)。
特征值分解:,则:
其中 是 在特征向量方向的投影。等 值的曲面是以特征向量为主轴、特征值平方根为半轴的椭球面。
多维高斯的两个实际问题:
-
参数量问题:协方差矩阵 有 个自由参数,当 很大时不可处理
- 解决方案:对角矩阵(特征独立假设)、各向同性()
- 相关算法:Factor Analysis, 概率PCA
-
单峰限制:单个高斯无法建模多峰数据
- 解决方案:高斯混合模型(GMM)
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
# 二维高斯分布可视化
mu = np.array([0.0, 0.0])
Sigma = np.array([[2.0, 1.5], [1.5, 2.0]]) # 正相关
x, y = np.meshgrid(np.linspace(-4, 4, 100), np.linspace(-4, 4, 100))
pos = np.dstack((x, y))
z = multivariate_normal(mu, Sigma).pdf(pos)
fig, ax = plt.subplots(figsize=(7, 6))
cp = ax.contourf(x, y, z, levels=20, cmap='Blues')
plt.colorbar(cp, label='Density')
# 画主轴(特征向量方向)
eigenvalues, eigenvectors = np.linalg.eigh(Sigma)
for val, vec in zip(eigenvalues, eigenvectors.T):
scale = 2 * np.sqrt(val)
ax.annotate('', xy=mu + scale * vec, xytext=mu - scale * vec,
arrowprops=dict(arrowstyle='<->', color='red', lw=2))
ax.set_title('2D Gaussian: Contours & Principal Axes')
ax.set_aspect('equal')
plt.tight_layout()
plt.savefig('2d_gaussian.png', dpi=150)
plt.show()6. 曲线拟合的概率视角
6.1 最大似然与最小二乘的等价性
噪声模型假设:目标值由真实函数加上高斯噪声生成:
其中 称为精度(precision)。
因此,给定 和参数 , 的条件概率为:
对数似然(对 个 i.i.d. 观测):
最大化似然 ⟺ 最小化平方误差:
对 最大化对数似然,等价于最小化:
这揭示了最小二乘法的概率含义:最小二乘是在高斯噪声假设下的最大似然估计。
噪声精度的 MLE:对 求导:
即预测方差等于训练集的平均残差平方和。
预测分布(对新数据点 的预测):
import numpy as np
from scipy.optimize import minimize
def log_likelihood_poly(w_beta, x, t, M):
"""多项式回归对数似然"""
w = w_beta[:M+1]
log_beta = w_beta[M+1]
beta = np.exp(log_beta)
y = np.polyval(w[::-1], x) # 注意系数顺序
N = len(t)
ll = (N/2) * np.log(beta) - (beta/2) * np.sum((y - t)**2) - (N/2) * np.log(2*np.pi)
return -ll # 负对数似然(最小化)
# 用梯度下降等价地最小化平方误差
Phi = polynomial_features(x_train, 3)
w_mle = np.linalg.lstsq(Phi, t_train, rcond=None)[0]
residuals = t_train - Phi @ w_mle
beta_mle = 1.0 / np.mean(residuals**2)
print(f"MLE参数 w: {w_mle}")
print(f"MLE噪声精度 β: {beta_mle:.4f}")
print(f"MLE噪声标准差 σ: {1/np.sqrt(beta_mle):.4f}")
# 预测区间
x_pred = np.linspace(0, 1, 200)
Phi_pred = polynomial_features(x_pred, 3)
y_pred = Phi_pred @ w_mle
std_pred = 1 / np.sqrt(beta_mle)
plt.figure(figsize=(8, 5))
plt.scatter(x_train, t_train, color='blue', s=50, label='训练数据')
plt.plot(x_pred, np.sin(2*np.pi*x_pred), 'g-', label='真实函数')
plt.plot(x_pred, y_pred, 'r-', label='MLE预测')
plt.fill_between(x_pred, y_pred - std_pred, y_pred + std_pred,
alpha=0.3, color='red', label='±1σ 预测区间')
plt.legend()
plt.title('最大似然估计:多项式回归(概率视角)')
plt.tight_layout()
plt.show()6.2 贝叶斯曲线拟合
频率派的局限:MLE 给出的是点估计,没有对参数不确定性的量化。在数据量少时,这会导致置信度过高。
贝叶斯方法:对参数 引入高斯先验:
这相当于假设每个参数都独立地接近零, 控制先验强度。
后验分布(利用高斯共轭性,后验仍是高斯):
其中:
关键洞察:MAP 估计(后验最大值)为:
这等价于 时的正则化最小二乘!正则化系数 的贝叶斯解释就是先验精度与噪声精度的比值。
贝叶斯预测分布:对所有可能的参数积分,得到预测分布:
两个不确定性来源:
- 数据噪声:,固定不变
- 参数不确定性:,在训练数据少的区域(外推区)更大
import numpy as np
import matplotlib.pyplot as plt
def bayesian_polynomial_regression(x_train, t_train, x_pred, degree, alpha, beta):
"""
贝叶斯多项式回归
alpha: 先验精度
beta: 噪声精度
返回后验均值和方差
"""
Phi_train = polynomial_features(x_train, degree)
Phi_pred = polynomial_features(x_pred, degree)
M1 = degree + 1
# 后验精度矩阵
S_N_inv = alpha * np.eye(M1) + beta * Phi_train.T @ Phi_train
S_N = np.linalg.inv(S_N_inv)
# 后验均值
m_N = beta * S_N @ Phi_train.T @ t_train
# 预测均值和方差
y_pred_mean = Phi_pred @ m_N
y_pred_var = 1/beta + np.array([phi @ S_N @ phi for phi in Phi_pred])
return m_N, S_N, y_pred_mean, y_pred_var
alpha, beta_val = 5e-3, 11.1 # 超参数
m_N, S_N, y_mean, y_var = bayesian_polynomial_regression(
x_train, t_train, x_test, 9, alpha, beta_val
)
y_std = np.sqrt(y_var)
plt.figure(figsize=(8, 5))
plt.scatter(x_train, t_train, color='blue', s=50, zorder=5, label='训练数据')
plt.plot(x_test, np.sin(2*np.pi*x_test), 'g-', lw=2, label='真实函数')
plt.plot(x_test, y_mean, 'r-', lw=2, label='贝叶斯预测均值')
plt.fill_between(x_test, y_mean - y_std, y_mean + y_std,
alpha=0.3, color='red', label='±1σ 贝叶斯不确定性')
plt.ylim(-1.5, 1.5)
plt.legend()
plt.title('贝叶斯曲线拟合(M=9,高斯先验)')
plt.tight_layout()
plt.show()
print("贝叶斯预测 vs MLE预测的关键区别:")
print("- 贝叶斯预测给出完整的预测分布,而非点估计")
print("- 在数据稀少区域(如端点),预测不确定性自动增大")
print("- 不需要单独的验证集来选择模型复杂度(原则上)")7. 模型选择
核心问题:如何选择合适的模型复杂度(如多项式阶数 ,或正则化参数 )?
方法一:验证集(Validation Set)
将数据分成训练集和验证集,在训练集上拟合模型,在验证集上评估性能,选择验证误差最小的模型。
问题:当数据量有限时,这种方法"浪费"了宝贵的训练数据。
方法二: 折交叉验证(-fold Cross-Validation)
将数据分成 份,轮流用其中 份训练,1 份验证,最终取平均验证误差:
数据集 D 分成 k 份: D₁, D₂, ..., Dₖ
for i = 1 to k:
训练集 = D \ Dᵢ
验证集 = Dᵢ
error_i = evaluate(train on 训练集, test on 验证集)
CV_error = mean(error_1, ..., error_k)
特例:(留一法,LOO-CV),偏差最小但计算代价最大。
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import Ridge
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
# k折交叉验证选择最优模型阶数
x_data = x_train.reshape(-1, 1)
cv_errors = []
for degree in range(1, 10):
model = Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('ridge', Ridge(alpha=1e-4))
])
scores = cross_val_score(model, x_data, t_train,
cv=5, scoring='neg_mean_squared_error')
cv_errors.append(-scores.mean())
best_degree = np.argmin(cv_errors) + 1
print(f"5折交叉验证最优阶数: M = {best_degree}")
plt.figure(figsize=(7, 4))
plt.plot(range(1, 10), cv_errors, 'b-o')
plt.xlabel('多项式阶数 M')
plt.ylabel('5折CV MSE')
plt.title('交叉验证选择模型复杂度')
plt.axvline(best_degree, color='r', linestyle='--', label=f'最优M={best_degree}')
plt.legend()
plt.tight_layout()
plt.show()方法三:信息准则
- AIC(Akaike Information Criterion):
- BIC(Bayesian Information Criterion):
其中 是参数数量, 是最大似然。BIC 对复杂模型的惩罚更重(包含 ),更倾向于选择简单模型。
方法四:贝叶斯模型选择
通过计算边际似然(模型证据):
证据自动对模型复杂度进行惩罚(奥卡姆剃刀原则):复杂模型必须用先验概率来支付参数的"代价"。
8. 维度灾难
维度灾难(Curse of Dimensionality) 是高维机器学习面临的核心挑战,由 Richard Bellman 提出。
8.1 球体体积集中在壳上
现象:在高维空间中,超球体的体积几乎全部集中在薄壳上(接近表面)。
维单位球体中,半径 的壳占总体积的比例为:
import numpy as np
import matplotlib.pyplot as plt
epsilon = 0.01 # 薄壳厚度
dims = range(1, 1001)
shell_fraction = [1 - (1 - epsilon)**D for D in dims]
plt.figure(figsize=(8, 4))
plt.plot(dims, shell_fraction, 'b-')
plt.xlabel('维度 D')
plt.ylabel('薄壳体积占比')
plt.title(f'ε={epsilon} 薄壳体积占超球体总体积的比例')
plt.axhline(0.99, color='r', linestyle='--', label='99%')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 数值结果
for D in [1, 2, 5, 10, 100]:
fraction = 1 - (1 - epsilon)**D
print(f"D={D:4d}: 壳体积占比 = {fraction:.6f}")8.2 高维空间中数据点稀疏
核心问题:要在 维空间中达到足够密度的训练样本,所需样本量以指数方式增长。
例如:在每个维度上将 分成 5 份,需要 个格子:
- :5 个格子
- :25 个格子
- :约 1000 万个格子
- :约 100 亿个格子
8.3 高维 Gaussian 的几何性质
从 维标准高斯中采样,样本到原点的距离分布峰值在 处:
import numpy as np
import matplotlib.pyplot as plt
def sample_gaussian_radius(D, n_samples=10000):
samples = np.random.randn(n_samples, D)
return np.linalg.norm(samples, axis=1)
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
for D in [1, 2, 5, 20, 100]:
radii = sample_gaussian_radius(D)
axes[0].hist(radii, bins=50, density=True, alpha=0.5, label=f'D={D}')
axes[1].hist(radii / np.sqrt(D), bins=50, density=True, alpha=0.5, label=f'D={D}')
axes[0].set_title('高维高斯样本到原点距离分布')
axes[0].set_xlabel('距离 r')
axes[0].legend()
axes[1].set_title('归一化距离 r/√D 分布')
axes[1].set_xlabel('r / √D')
axes[1].legend()
plt.tight_layout()
plt.show()8.4 维度灾难的影响与应对
影响:
- KNN(K近邻)等基于距离的方法在高维下效果急剧下降
- 需要样本量随维度指数增长才能保持同等学习性能
- 所有数据点之间的距离趋于相同(距离集中现象)
应对策略:
- 特征选择(Feature Selection):只保留最相关的特征
- 降维(Dimensionality Reduction):PCA, t-SNE, UMAP
- 正则化(Regularization):约束模型的有效复杂度
- 利用数据的低维流形结构:真实数据往往存在于高维空间的低维流形上
重要认识:维度灾难并没有使机器学习无效!这是因为真实数据不是在高维空间中均匀分布的,而是集中在较低维的流形上,这使得机器学习仍然可行。
9. 决策论
概率论告诉我们如何描述和更新不确定性;决策论(Decision Theory) 告诉我们在不确定性下如何做出最优决策。
场景:已知输入 和后验分布 ,应该将 分到哪个类?
9.1 最小误分类率
决策区域(Decision Region):将输入空间划分为 个区域 ,落入 的点被分为 类。
误分类概率:
两类问题的最优规则(最小化误分类率):
即总是选择后验概率最大的类——这就是最大后验(MAP)分类规则。
伪代码:MAP分类器
输入: x, 模型 p(x|C_k), 先验 p(C_k)
输出: 预测类别
1. 对每个类 k:
计算 p(C_k|x) ∝ p(x|C_k) * p(C_k)
2. 返回 argmax_k p(C_k|x)
几何意义:决策边界 是满足 的超曲面,即后验概率相等的点集。
9.2 最小期望损失
在许多实际应用中,不同类型的错误代价不同。例如:
- 癌症诊断:将癌症误诊为正常(漏诊)代价远大于将正常误诊为癌症(误诊)
- 垃圾邮件过滤:错过一封重要邮件 vs. 收到一封垃圾邮件,哪个损失更大?
损失矩阵(Loss Matrix): 表示真实类别为 但被分到 时的损失()。
期望损失(Expected Loss):
最优决策规则:将 分到使期望损失最小的类:
import numpy as np
def min_expected_loss_decision(posterior, loss_matrix):
"""
posterior: shape (K,) — 各类的后验概率
loss_matrix: shape (K, K) — L[k,j] = 真实为k分到j的损失
返回最优决策类别索引
"""
# 期望损失 [j] = sum_k L[k,j] * p(C_k|x)
expected_losses = loss_matrix.T @ posterior
return np.argmin(expected_losses)
# 二分类例子:医疗诊断
# 类0: 正常, 类1: 癌症
posterior = np.array([0.7, 0.3]) # P(正常|x)=0.7, P(癌症|x)=0.3
# 对称损失(0-1损失)
L_symmetric = np.array([[0, 1],
[1, 0]])
# 非对称损失(漏诊代价极高)
L_asymmetric = np.array([[0, 1], # 正常→误诊为癌: 代价1
[10, 0]]) # 癌症→漏诊: 代价10
dec_sym = min_expected_loss_decision(posterior, L_symmetric)
dec_asy = min_expected_loss_decision(posterior, L_asymmetric)
print(f"后验概率: P(正常|x)={posterior[0]}, P(癌症|x)={posterior[1]}")
print(f"对称损失下决策: 类{dec_sym} ({'正常' if dec_sym==0 else '癌症'})")
print(f"非对称损失下决策: 类{dec_asy} ({'正常' if dec_asy==0 else '癌症'})")
print("=> 即使癌症后验只有0.3,考虑漏诊代价后仍应诊断为癌症!")9.3 拒绝选项
当最高后验概率不超过阈值 时,拒绝做出决策(交给专家判断):
直觉:当模型对某个输入不确定时(所有类的后验都接近),强行做出决策可能是不可靠的。
应用场景:
- 医疗诊断:不确定的案例转给医生复查
- 自动驾驶:不确定场景由人工接管
- 金融风控:可疑交易人工审核
阈值 的选择: 越高,拒绝的样本越多(覆盖率下降),但对接受的样本准确率越高(精度提升)。ROC 曲线下的面积(AUC)是衡量这种权衡的常用指标。
def predict_with_rejection(posteriors, threshold):
"""
posteriors: shape (N, K)
threshold: 拒绝阈值
返回决策(-1表示拒绝)
"""
max_posteriors = np.max(posteriors, axis=1)
decisions = np.argmax(posteriors, axis=1)
decisions[max_posteriors < threshold] = -1 # -1 = 拒绝
return decisions
# 示例
np.random.seed(42)
N = 1000
posteriors = np.random.dirichlet([1, 1, 1], N) # 3类随机后验
for theta in [0.4, 0.6, 0.8, 0.95]:
decisions = predict_with_rejection(posteriors, theta)
rejection_rate = np.mean(decisions == -1)
print(f"θ={theta:.2f}: 拒绝率={rejection_rate:.2%}")9.4 推断与决策的分离
Bishop 提出三种解决判别问题的方法,从完整到简化:
方法一:生成模型(Generative Models)
- 学习类条件密度 和先验
- 用贝叶斯定理计算后验
- 用决策论做最终决策
优点:可以生成新数据;可以检测异常值(低密度区域)
缺点:需要大量数据准确估计 ;分类不需要的密度信息被浪费
代表:朴素贝叶斯、高斯判别分析(GDA)、GMM 分类
方法二:判别模型(Discriminative Models)
直接建模后验 ,然后决策。
优点:更直接,不需要建模 ;参数量少;通常泛化性能更好
代表:逻辑回归、条件随机场(CRF)
方法三:判别函数(Discriminant Functions)
直接学习输入到类别的映射 ,完全绕过概率。
优点:最简单直接
缺点:没有不确定性信息;无法拒绝选项;无法使用损失矩阵
代表:SVM、感知机、决策树(以 hard 预测为输出时)
选择建议:
| 需求 | 推荐方法 |
|---|---|
| 只需要分类结果 | 判别函数 |
| 需要概率输出(用于决策/校准) | 判别模型 |
| 需要生成新样本/异常检测 | 生成模型 |
9.5 回归的损失函数
回归问题的期望损失:
对于给定 ,最优预测 是使条件期望损失最小的值。
平方损失(L2 Loss):
最优预测:
即条件均值。推导(对 求导令其为零):
期望平方误差的分解(Bias-Variance Decomposition):
绝对值损失(L1 Loss):
最优预测是条件中位数(Median)。
Minkowski 损失:
- :最优预测 = 条件中位数
- :最优预测 = 条件均值
- :最优预测 = 条件众数(Mode)
import numpy as np
import matplotlib.pyplot as plt
# 偏度非对称分布:均值、中位数、众数的比较
np.random.seed(42)
# 模拟一个右偏分布
data = np.concatenate([np.random.normal(2, 0.5, 800),
np.random.normal(5, 1.0, 200)])
mean_val = np.mean(data)
median_val = np.median(data)
plt.figure(figsize=(8, 4))
plt.hist(data, bins=50, density=True, alpha=0.7, color='steelblue')
plt.axvline(mean_val, color='red', lw=2, linestyle='--', label=f'均值 (L2最优)={mean_val:.2f}')
plt.axvline(median_val, color='green', lw=2, linestyle='--', label=f'中位数 (L1最优)={median_val:.2f}')
plt.legend()
plt.title('不同损失函数下的最优预测值')
plt.tight_layout()
plt.show()
# L2 vs L1 损失的鲁棒性比较
y_pred_vals = np.linspace(-2, 8, 500)
t_examples = np.array([1.0, 2.0, 2.5, 3.0, 10.0]) # 最后一个是异常值
l2_losses = [np.sum((y - t_examples)**2) for y in y_pred_vals]
l1_losses = [np.sum(np.abs(y - t_examples)) for y in y_pred_vals]
plt.figure(figsize=(8, 4))
plt.plot(y_pred_vals, l2_losses, 'r-', label='L2总损失(最优=均值)')
plt.plot(y_pred_vals, l1_losses, 'b-', label='L1总损失(最优=中位数)')
plt.axvline(np.mean(t_examples), color='r', linestyle='--', alpha=0.5)
plt.axvline(np.median(t_examples), color='b', linestyle='--', alpha=0.5)
plt.xlabel('预测值 y')
plt.ylabel('总损失')
plt.title('L2 vs L1 损失对异常值的敏感性')
plt.legend()
plt.tight_layout()
plt.show()10. 信息论
信息论为机器学习提供了量化不确定性、衡量信息量、比较概率分布的数学工具。
10.1 熵
信息量的定义:观察到事件 所获得的信息量应该满足:
- 概率越小的事件,信息量越大
- 独立事件的信息量可以相加:
满足以上条件的唯一函数形式(至多差一个正常数)是:
负号保证信息量非负(因为 )。
香农熵(Entropy):随机变量 的平均信息量:
约定 (极限意义)。对于连续变量:
熵的性质:
- (离散)
- 在均匀分布时最大(最不确定)
- 在确定性事件时为 0
二元熵:,:
import numpy as np
import matplotlib.pyplot as plt
def binary_entropy(mu):
eps = 1e-15 # 防止log(0)
mu = np.clip(mu, eps, 1 - eps)
return -mu * np.log2(mu) - (1 - mu) * np.log2(1 - mu)
def discrete_entropy(probs):
"""计算离散分布的香农熵(以2为底,单位:bits)"""
probs = np.array(probs)
probs = probs[probs > 0] # 排除0概率
return -np.sum(probs * np.log2(probs))
# 二元熵曲线
mu_vals = np.linspace(0, 1, 1000)
H_vals = binary_entropy(mu_vals)
plt.figure(figsize=(8, 4))
plt.plot(mu_vals, H_vals, 'b-', lw=2)
plt.xlabel('概率 μ = P(x=1)')
plt.ylabel('熵 H (bits)')
plt.title('二元熵函数:H(μ) = -μlog₂μ - (1-μ)log₂(1-μ)')
plt.axvline(0.5, color='r', linestyle='--', label='μ=0.5: 最大熵=1 bit')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 几个分布的熵
examples = {
"公平硬币 (均匀)": [0.5, 0.5],
"偏硬币 (0.9/0.1)": [0.9, 0.1],
"确定事件": [1.0, 0.0],
"均匀4面骰": [0.25]*4,
"均匀6面骰": [1/6]*6,
}
print("各分布的熵:")
for name, probs in examples.items():
H = discrete_entropy([p for p in probs if p > 0])
print(f" {name}: H = {H:.4f} bits")最大熵分布:
- 离散, 个等可能状态:均匀分布,
- 连续,给定均值和方差:高斯分布(这是高斯分布在自然界普遍出现的信息论原因!)
- 连续,只约束非负和均值 :指数分布
联合熵与条件熵:
链式法则:
互信息(Mutual Information):
互信息衡量"了解 之后, 的不确定性减少了多少",可以作为变量之间相关性的度量(不限于线性相关)。
10.2 KL 散度与互信息
KL 散度(相对熵, Kullback-Leibler Divergence):衡量分布 与真实分布 的差异:
KL 散度的性质:
- (吉布斯不等式,Gibbs' Inequality)
- (几乎处处)
- 非对称:(不是距离!)
吉布斯不等式的证明(利用 ):
因此 。
KL 散度与最大似然的联系:
假设真实分布为 ,我们用参数化模型 来近似:
最小化 等价于最大化期望对数似然:
用样本近似期望:,这正是 MLE!
互信息与KL散度的关系:
互信息是联合分布与独立假设分布之间的 KL 散度,衡量 和 偏离独立性的程度。
import numpy as np
from scipy.special import rel_entr # KL散度的逐元素版本
def kl_divergence(p, q):
"""
计算 KL(p||q)
p, q: 离散概率分布 (numpy arrays)
"""
eps = 1e-15
p = np.clip(p, eps, 1)
q = np.clip(q, eps, 1)
return np.sum(rel_entr(p, q)) # sum(p * log(p/q))
# 示例:高斯分布的KL散度
def kl_gaussian(mu1, sigma1, mu2, sigma2):
"""计算 KL(N(mu1,sigma1^2) || N(mu2,sigma2^2)) 的解析解"""
return (np.log(sigma2/sigma1) +
(sigma1**2 + (mu1 - mu2)**2) / (2 * sigma2**2) - 0.5)
# 固定N(0,1),改变另一个分布
mu2_vals = np.linspace(-3, 3, 100)
kl_vals_1 = [kl_gaussian(0, 1, mu2, 1) for mu2 in mu2_vals] # 只改变均值
kl_vals_2 = [kl_gaussian(0, 1, 0, sigma2) for sigma2 in np.linspace(0.1, 4, 100)]
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].plot(mu2_vals, kl_vals_1, 'b-', lw=2)
axes[0].set_xlabel('μ₂ (σ₂=1固定)')
axes[0].set_ylabel('KL(N(0,1) || N(μ₂,1))')
axes[0].set_title('KL散度 vs 均值偏移')
axes[0].axvline(0, color='r', linestyle='--', label='KL=0 (相同分布)')
axes[0].legend()
sigma2_vals = np.linspace(0.1, 4, 100)
kl_vals_2 = [kl_gaussian(0, 1, 0, s2) for s2 in sigma2_vals]
axes[1].plot(sigma2_vals, kl_vals_2, 'g-', lw=2)
axes[1].set_xlabel('σ₂ (μ₂=0固定)')
axes[1].set_ylabel('KL(N(0,1) || N(0,σ₂))')
axes[1].set_title('KL散度 vs 方差变化')
axes[1].axvline(1, color='r', linestyle='--', label='KL=0 (σ₂=1)')
axes[1].legend()
plt.tight_layout()
plt.savefig('kl_divergence.png', dpi=150)
plt.show()
# 非对称性演示
print("\nKL散度的非对称性:")
p = np.array([0.7, 0.2, 0.1])
q = np.array([0.4, 0.4, 0.2])
print(f" KL(p||q) = {kl_divergence(p, q):.4f}")
print(f" KL(q||p) = {kl_divergence(q, p):.4f}")
print(f" KL(p||q) ≠ KL(q||p), KL散度是非对称的")交叉熵(Cross-Entropy):
在机器学习中,当真实分布 固定时,最小化交叉熵等价于最小化 KL 散度,也等价于 MLE。这也是分类问题中常用 Cross-Entropy Loss 的理论依据。
import numpy as np
def cross_entropy_loss(y_true_onehot, y_pred_probs):
"""
分类交叉熵损失
y_true_onehot: shape (N, K) 真实标签(one-hot)
y_pred_probs: shape (N, K) 预测概率(softmax输出)
"""
eps = 1e-15
y_pred_probs = np.clip(y_pred_probs, eps, 1)
return -np.mean(np.sum(y_true_onehot * np.log(y_pred_probs), axis=1))
# 示例:3分类,5个样本
np.random.seed(42)
y_true = np.array([[1,0,0], [0,1,0], [0,0,1], [1,0,0], [0,1,0]])
y_pred_good = np.array([[0.9, 0.05, 0.05],
[0.05, 0.9, 0.05],
[0.05, 0.05, 0.9],
[0.8, 0.1, 0.1],
[0.1, 0.8, 0.1]])
y_pred_bad = np.array([[0.4, 0.3, 0.3],
[0.3, 0.4, 0.3],
[0.3, 0.3, 0.4],
[0.5, 0.3, 0.2],
[0.2, 0.5, 0.3]])
print(f"好预测的交叉熵: {cross_entropy_loss(y_true, y_pred_good):.4f}")
print(f"差预测的交叉熵: {cross_entropy_loss(y_true, y_pred_bad):.4f}")总结:第一章知识体系
PRML 第一章知识图谱
│
├── 核心示例: 多项式曲线拟合
│ ├── 最小二乘法(正规方程)
│ ├── 过拟合与欠拟合
│ └── 正则化(Ridge/L2)
│
├── 概率论基础
│ ├── 加法规则(边际化)
│ ├── 乘法规则
│ ├── 贝叶斯定理
│ └── 连续密度 / 期望 / 协方差
│
├── 两大学派
│ ├── 频率派 → MLE → 最优化问题
│ └── 贝叶斯派 → MAP / 后验预测 → 积分问题
│
├── 高斯分布
│ ├── MLE(均值无偏,方差有偏)
│ └── 贝塞尔校正
│
├── 概率视角的曲线拟合
│ ├── 高斯噪声模型 → MLE ≡ 最小二乘
│ └── 高斯先验 → MAP ≡ 正则化最小二乘
│
├── 模型选择
│ ├── 交叉验证
│ └── 信息准则 (AIC/BIC)
│
├── 维度灾难
│ ├── 体积集中在表面
│ └── 指数增长的样本需求
│
├── 决策论
│ ├── 最小误分类率 → MAP规则
│ ├── 最小期望损失 → 损失矩阵
│ ├── 拒绝选项
│ ├── 推断与决策的分离(三种方法)
│ └── 回归损失:L2→均值, L1→中位数
│
└── 信息论
├── 熵 H[X]
├── 联合熵 / 条件熵
├── KL散度(非对称,≥0)
├── 互信息 I[X;Y] = KL(p(x,y)||p(x)p(y))
└── 交叉熵 ≡ MLE 目标函数贯穿全章的核心思想:
- 不确定性无处不在:数据有噪声,模型有参数不确定性,预测有误差
- 概率论是处理不确定性的语言:加法规则+乘法规则推导出贝叶斯定理
- MLE 与最小二乘是等价的(高斯噪声假设下),正则化对应高斯先验
- 过拟合 = 有限数据下的最大似然:贝叶斯方法通过积分避免过拟合
- 决策需要损失函数:概率是推断的工具,损失函数决定最终行动
参考资料:
- Christopher M. Bishop, Pattern Recognition and Machine Learning, Springer, 2006
- 徐亦达《概率图模型》课程笔记(GitHub: whiteboard_ml_notes)
- 张志华《机器学习》讲义(MachineLearningNotes)