CS336 · 2025 年春季 · 第 3 讲
最好的学习方式是亲自动手。第二好的方式是从别人的经验中学习。
目录
概览
这份笔记回顾了现代大型语言模型是如何偏离 2017 年原始 Transformer 的,更重要的是,解释了为什么会这样。整体视角是经验主义的:观察 19 个以上稠密模型的发布版本,看看哪些设计最终留了下来。
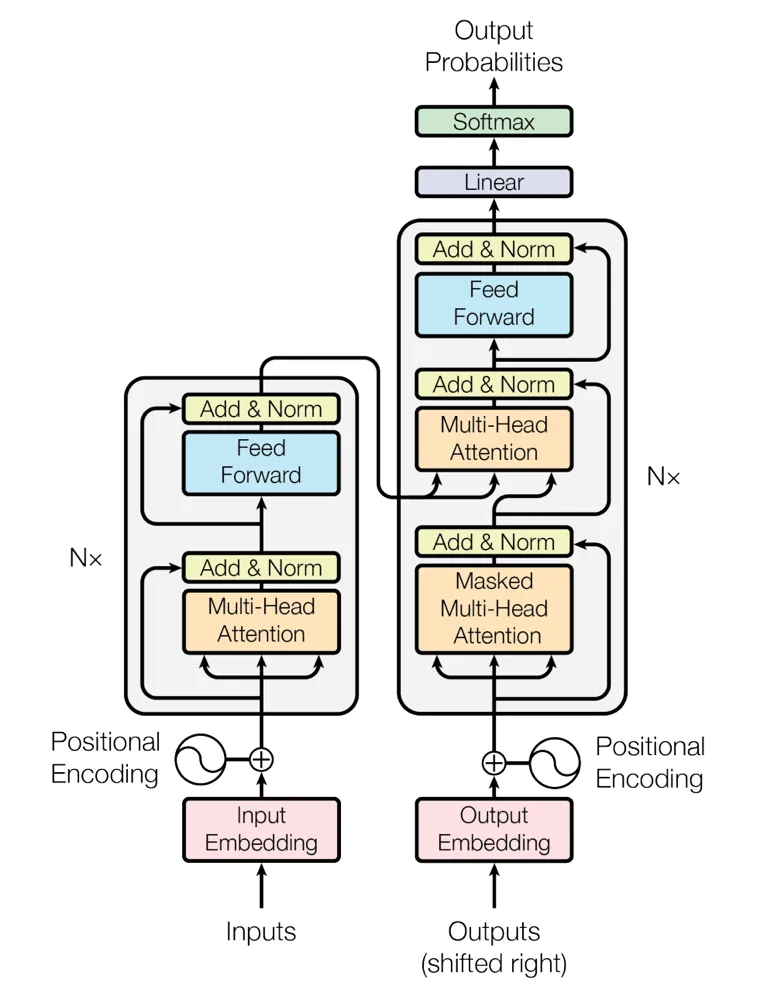
起点——原始 Transformer(Vaswani 2017):
- 位置嵌入:正弦和余弦
- FFN:ReLU 激活
- 归一化:post-norm LayerNorm
现代 LLM(例如 CS336 作业)通常使用:
- Pre-norm——在 block 前做 LayerNorm,而不是在后面
- RoPE——旋转位置嵌入
- SwiGLU——使用门控 FFN,而不是简单的 ReLU
- 无 bias 项——所有线性层和归一化层都去掉偏置
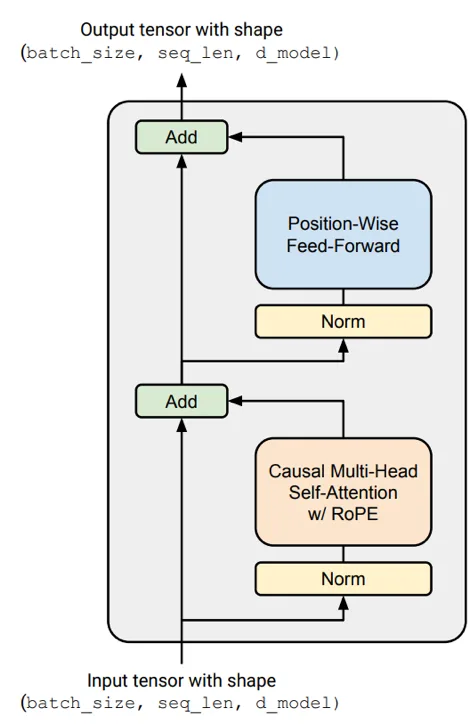
1. 归一化
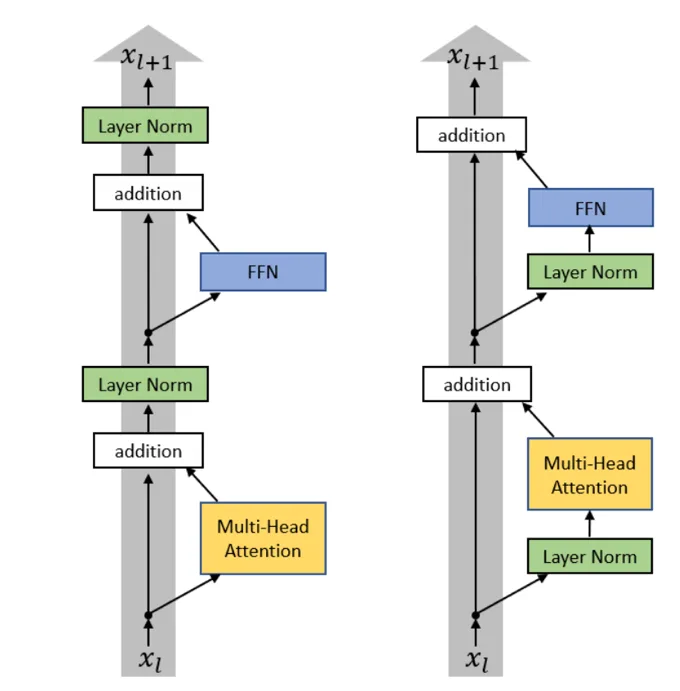
Pre-norm 与 Post-norm
Post-norm(原始 Transformer):
x -> [Attention] -> x + attn_out -> LayerNorm -> ...
Pre-norm(现代做法):
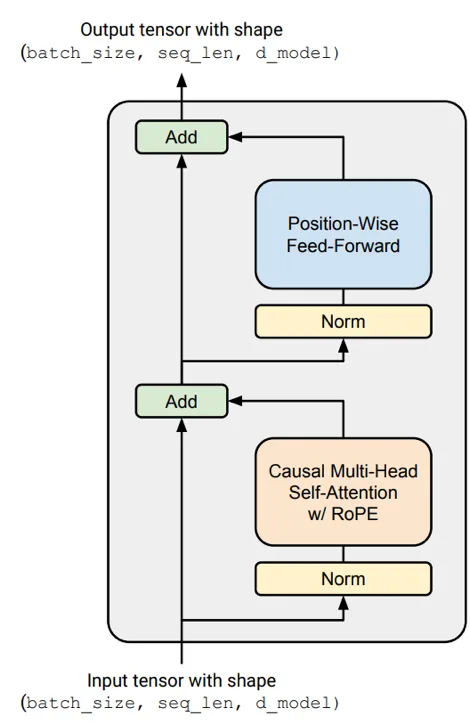
x -> LayerNorm -> [Attention] -> x + attn_out -> ...Pre-norm 将 LayerNorm 放在残差分支内部,因此残差路径上传递的是未经归一化的信号。这是到 2024 年几乎所有人都认同的单一最重要架构选择。
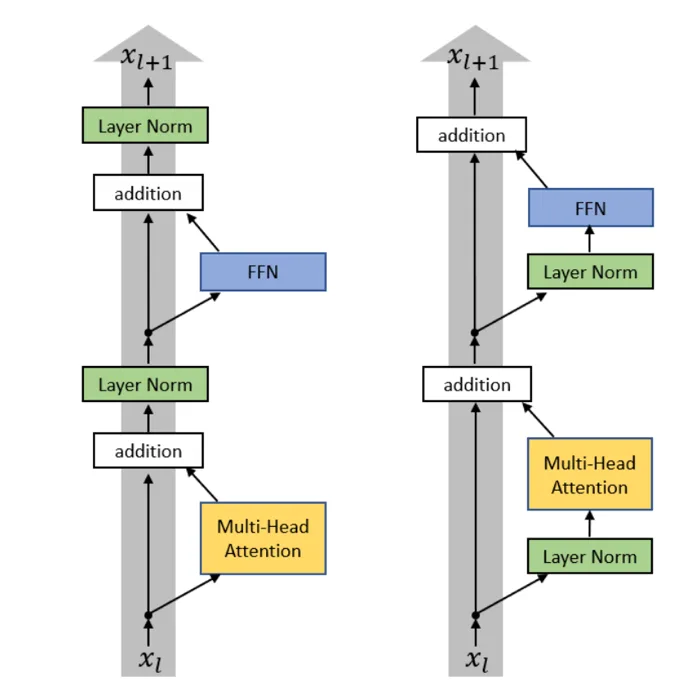
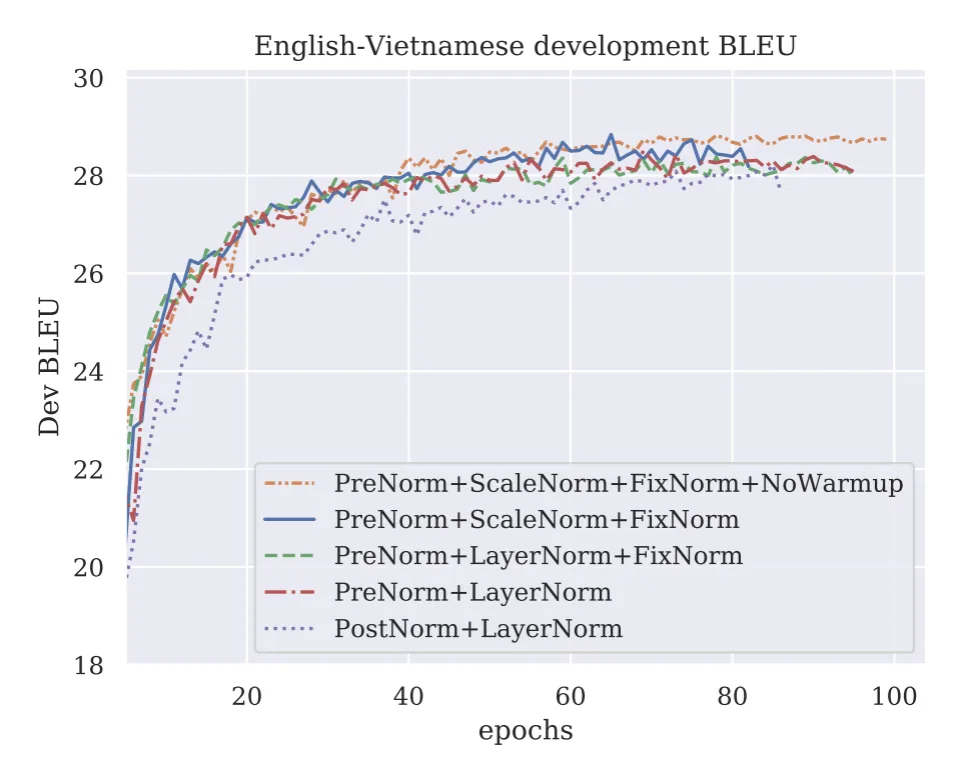
为什么 pre-norm 更优:
| 解释 | 来源 |
|---|---|
| Post-norm 会削弱沿残差流传播的梯度 | Xiong et al. 2020 |
| Post-norm 会导致梯度尖峰 | Salazar & Nguyen 2019 |
| Pre-norm 允许大网络使用更大的学习率 | 通用实践 |
不同模型采用情况:
| Pre-norm | Post-norm |
|---|---|
| LLaMA 1/2/3, PaLM, Chinchilla, T5 v1.1, GPT-J, Mistral, OLMo | GPT-1/2/3, OPT, BERT, 原始 Transformer |
| 几乎所有 2023 年及之后的模型 | 典型离群点:OPT-350M(原因未知) |
“双重归一化”(近年做法): 一些模型(Grok、Gemma 2、OLMo 2)会在残差流外部再加一个 LayerNorm。这不是 post-norm——因为残差路径本身仍然没有被归一化。
LayerNorm 与 RMSNorm
LayerNorm——对均值和方差做归一化,再应用可学习的缩放 γ 和偏置 β:
RMSNorm——不减去均值,也没有偏置,只根据均方根做归一化:
import torch
import torch.nn as nn
class RMSNorm(nn.Module):
def __init__(self, d_model: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(d_model)) # 只有 gamma,没有 beta
def forward(self, x: torch.Tensor) -> torch.Tensor:
rms = x.pow(2).mean(dim=-1, keepdim=True).add(self.eps).sqrt()
return (x / rms) * self.weight为什么是 RMSNorm 而不是 LayerNorm?
最直观的回答——“FLOPs 更少”——其实有误导性。矩阵乘法才是 FLOPs 的主要来源;去掉一些归一化操作,对总 FLOPs 的影响很小。
真正的原因是 [Ivanov et al. 2023] 所指出的:内存带宽。归一化是典型的内存带宽受限操作(算术强度低)。参数更少 -> 内存访问更少 -> 能带来可测量的实际运行时间提升。
关键结论:FLOPs 不等于运行时间。必须始终考虑内存访问模式。
| 模型家族 | 归一化 |
|---|---|
| GPT-1/2/3, OPT, GPT-J, BLOOM | LayerNorm |
| LLaMA 系列, PaLM, Chinchilla, T5 | RMSNorm |
去掉 Bias
大多数现代 Transformer 都会从所有线性层和归一化层中移除 bias 项。
nn.Linear(d_model, d_ff, bias=False) # 现代做法原因: 需要在内存中搬运的参数更少(和 RMSNorm 的逻辑相同),同时在大学习率下优化通常更稳定。
2. 激活函数与 FFN 设计
激活函数“动物园”
ReLU GeLU Swish ELU GLU GeGLU ReGLU SeLU SwiGLU LiGLU目前这个领域基本已经收敛到 SwiGLU 或 GeGLU。下面按演化过程来看。
标准激活函数
ReLU——原始 Transformer、T5、Gopher、Chinchilla、OPT:
GeLU——GPT-1/2/3、BLOOM、GPT-NeoX:
门控线性单元(GLU 家族)
在第一层投影上增加一个逐元素的门控:
这个 gate 用来控制 value 分支有多少信息可以通过。这会额外引入第二个权重矩阵 。
| 名称 | Gate | 公式 |
|---|---|---|
| ReGLU | ReLU | |
| GeGLU | GeLU | |
| SwiGLU | Swish = x·sigmoid(x) |
SwiGLU 实现(LLaMA、PaLM、Mistral):
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLU_FFN(nn.Module):
"""
d_ff 默认设为 8/3 * d_model,
这样参数量可以与 4x ReLU FFN 保持可比;
否则额外的 V 矩阵会让参数量增加约 50%。
"""
def __init__(self, d_model: int, d_ff: int | None = None):
super().__init__()
if d_ff is None:
d_ff = int(8 / 3 * d_model)
d_ff = 256 * ((d_ff + 255) // 256) # 向上取整到 256 的倍数
self.w1 = nn.Linear(d_model, d_ff, bias=False) # gate(Swish)
self.v = nn.Linear(d_model, d_ff, bias=False) # value(线性)
self.w2 = nn.Linear(d_ff, d_model, bias=False) # 输出投影
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.w2(F.silu(self.w1(x)) * self.v(x))2/3 缩放规则
GLU 变体多了一个额外的权重矩阵 V。为了让总参数量和 d_ff = 4 × d_model 的 ReLU FFN 保持大致一致:
| 模型 | d_ff / d_model |
|---|---|
| PaLM | 4.0 |
| Mistral 7B | 3.5 |
| LLaMA-2 70B | 3.5 |
| LLaMA 70B / DeepSeek 67B | 2.68 |
| Qwen 14B | 2.67 |
| T5 v1.1 | 2.5 |
| T5(11B,非 GLU) | 64.0——明显离群,后续版本已改进 |
GLU 真的有帮助吗?
有,而且相当稳定 [Shazeer 2020, Narang et al. 2020]——不过提升幅度不算大。GPT-3 使用 GeLU,效果依然非常好。值得注意的非 GLU 离群模型包括:Nemotron 340B(Squared ReLU)、Falcon 2 11B(ReLU)。
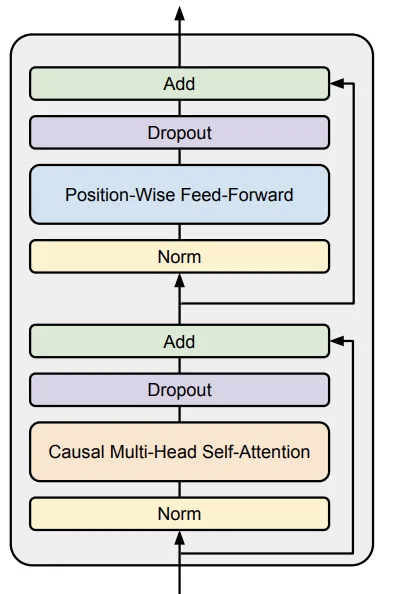
串行层与并行层
一些模型(GPT-J、PaLM、Command A)会让 Attention 和 FFN 并行执行,而不是串行:
x -> LayerNorm --+-> Attention --\
+-> FFN -------- + -> outputLayerNorm 可以共享,矩阵乘法也更容易融合。相关消融实验数据不多,但确实有可测量的计算收益。
3. 位置嵌入
Transformer 天生对排列是等变的——如果没有位置信息,词序是不可见的。这个领域大致经历了四代方案。
第一代:正弦/余弦(原始 Transformer)
它被直接加到 token embedding 上。问题: 中会包含类似 这样的交叉项,而这些项依赖于绝对位置。
第二代:可学习的绝对位置编码(GPT-1/2/3、OPT)
用可学习查找表 替代固定正弦。问题依旧——它仍然不是真正的相对位置表示。
第三代:相对偏置(T5、Gopher、Chinchilla)
把位置信息作为 bias 注入到 attention score 中。它是相对的,但不是通过内积表达——因此组合性质不够优雅。
第四代:RoPE——旋转位置嵌入
使用模型包括:GPT-J、PaLM、LLaMA 1/2/3,以及几乎所有 2024 年之后的模型。
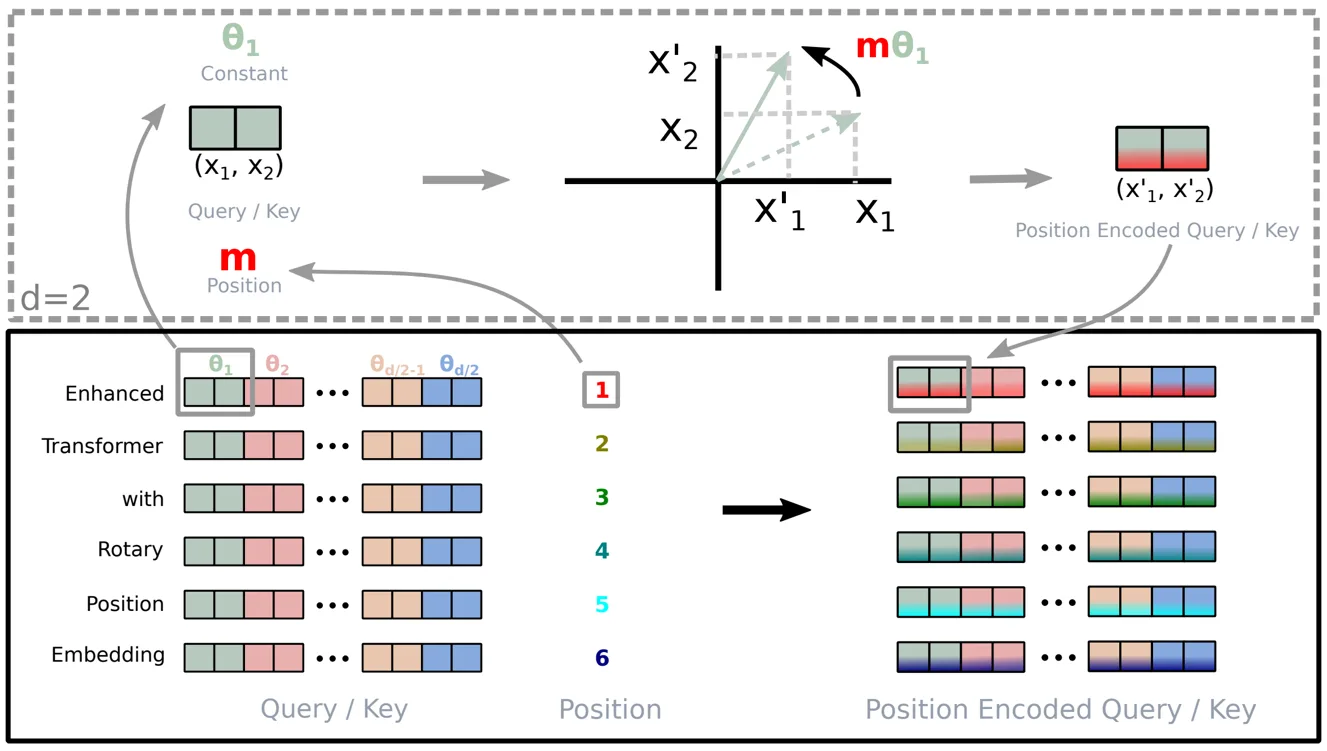
RoPE:核心思想
期望性质: 编码函数 满足:
也就是说,点积只依赖于相对位置 。
关键洞见: 内积在旋转下是不变的。如果把两个向量按不同角度旋转,它们的点积变化只取决于这些角度的差值。
-> 于是把位置 编码为:将向量按与 成比例的角度旋转。
-> 这样一来, 就只会捕捉到 。
RoPE 的数学形式
对于每一对维度 ,在位置 处施加一个角度为 的二维旋转:
- 乘法式,而不是加法式——不会和 token embedding 产生交叉项
- 在每一层注意力中都对 Q 和 K 应用,以保证整个网络里注意力都体现相对位置信息

RoPE 实现
import torch
import torch.nn as nn
def get_rope_cos_sin(seq_len: int, d_head: int, base: int = 10000,
device=None, dtype=None):
half_d = d_head // 2
k = torch.arange(half_d, device=device, dtype=torch.float32)
theta = 1.0 / (base ** (2 * k / d_head)) # (half_d,)
pos = torch.arange(seq_len, device=device, dtype=torch.float32)
angles = torch.outer(pos, theta) # (seq_len, half_d)
angles = torch.cat([angles, angles], dim=-1) # (seq_len, d_head)
return angles.cos().to(dtype=dtype), angles.sin().to(dtype=dtype)
def rotate_half(x: torch.Tensor) -> torch.Tensor:
half = x.shape[-1] // 2
return torch.cat([-x[..., half:], x[..., :half]], dim=-1)
def apply_rope(x: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor) -> torch.Tensor:
"""x: (batch, n_heads, seq_len, d_head)"""
cos = cos[None, None] # 在 batch 和 heads 维度上广播
sin = sin[None, None]
return x * cos + rotate_half(x) * sin对比表
| 方法 | 应用位置 | 是否真正相对? | 模型 |
|---|---|---|---|
| 正弦编码 | Token embedding | 否(存在交叉项) | 原始 Transformer |
| 可学习绝对位置编码 | Token embedding | 否 | GPT-1/2/3, OPT |
| 相对偏置 | Attention score | 是 | T5, Gopher |
| RoPE | Q 和 K 向量 | 是(精确) | LLaMA, PaLM, 多数 2024+ 模型 |
4. 超参数
大多数 LLM 的超参数其实相当保守。
d_ff / d_model 比例
标准规则: d_ff = 4 × d_model(非 GLU)或 d_ff = 8/3 × d_model(GLU)。
经验上,范围在 1 到 10 之间的值通常都接近最优 [Kaplan et al. 2020]。T5 的 64× 比例在技术上能工作,但 T5 v1.1(改进版)已经把它降到了 2.5——这说明 64× 很可能并不理想。
Head Dimension
标准假设:
| 模型 | n_heads | d_head | d_model | 比例 |
|---|---|---|---|---|
| GPT-3 | 96 | 128 | 12288 | 1.0 |
| T5 | 128 | 128 | 1024 | 16.0 |
| LLaMA 2 | 64 | 128 | 8192 | 1.0 |
| PaLM | 48 | 256 | 18432 | 1.48 |
多数模型的比例都大于 1。关于“低秩瓶颈” [Bhojanapalli et al. 2020] 的理论担忧,在实践中并没有明显出现。
长宽比(深度 vs 宽度)
d_model / n_layers 在大多数模型中通常落在 100 到 200 之间。
| 模型 | d_model / n_layers |
|---|---|
| BLOOM | 205 |
| T5 v1.1 | 171 |
| PaLM 540B | 156 |
| GPT-3 / Mistral / Qwen | ~102 |
| LLaMA / LLaMA 2 | ~102 |
为什么不做得特别深? 深层模型更难在多 GPU 上做 pipeline,并且会增加推理阶段的串行延迟。通常是系统层面的约束——而不是模型质量本身——决定了这一点。
词表大小
| 设置 | 典型大小 |
|---|---|
| 单语 | 30k 到 50k |
| 多语 / 生产环境 | 100k 到 250k |
| 模型 | 词表大小 |
|---|---|
| LLaMA | 32,000 |
| GPT-2/3 | 50,257 |
| GPT-4 | 100,276 |
| PaLM | 256,000 |
| Qwen 15B | 152,064 |
| mT5 | 250,000 |
正则化
趋势: 新一些的模型通常去掉 dropout,但保留 weight decay。
| 模型 | Dropout | Weight Decay |
|---|---|---|
| GPT-2, T5, GPT-3, OPT | 0.1 | 0.1 |
| T5 v1.1, PaLM, LLaMA | 0.0 | 0.1 |
为什么还要 weight decay? [Andriushchenko et al. 2023] 指出,这主要不是为了控制过拟合。因为训练 token 数量往往达到数万亿(数据量甚至超过参数量),过拟合并不是核心问题。Weight decay 主要通过和余弦学习率调度的相互作用来影响优化动态。
5. 训练稳定性技巧
大多数不稳定性的根源都是 softmax。指数函数会爆炸。
如果某个 变得很大,就会带来数值溢出、梯度消失和 loss spike。
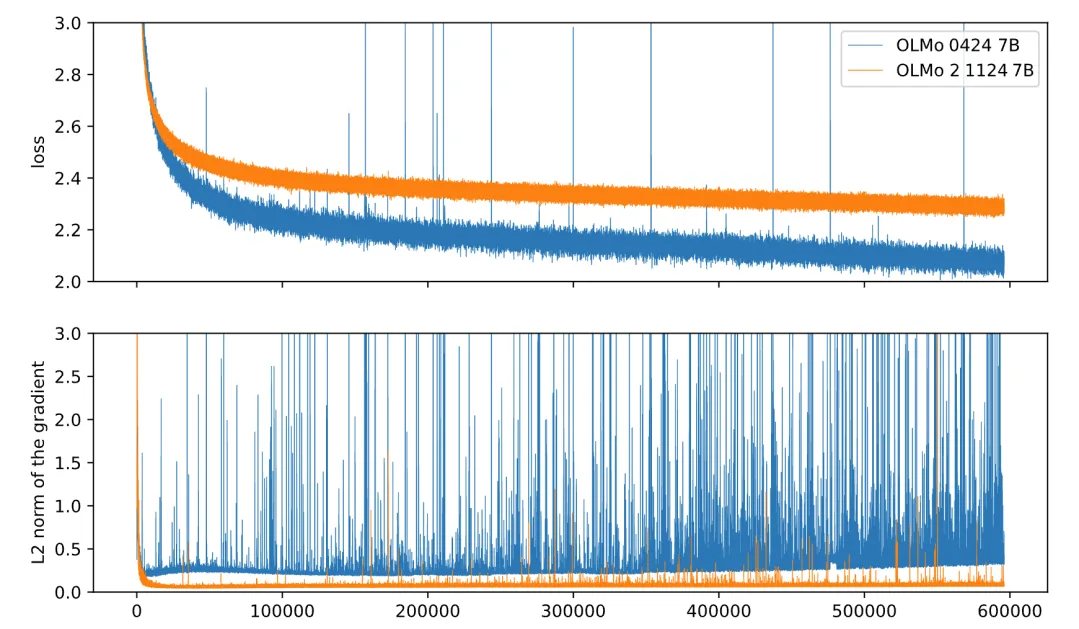
技巧 1:Z-Loss(输出层 Softmax)
由 PaLM 推广。额外加入一个辅助损失,用来惩罚过大的 log-partition 值:
import torch
import torch.nn.functional as F
def z_loss(logits: torch.Tensor, alpha: float = 1e-4) -> torch.Tensor:
"""
惩罚 logits 的 log-sum-exp 平方。
让 logits 保持较小 -> 输出 softmax 更稳定。
PaLM、Baichuan 2、DCLM、OLMo 2 使用了这一技巧。
"""
log_z = torch.logsumexp(logits, dim=-1)
return alpha * (log_z ** 2).mean()
# 在训练循环中:
loss = F.cross_entropy(logits.view(-1, vocab), labels.view(-1))
loss = loss + z_loss(logits)使用模型: PaLM、Baichuan 2(2023)、DCLM(2024)、OLMo 2(2025)
技巧 2:QK Norm(注意力 Softmax)
在做点积之前,对 Query 和 Key 向量先做 RMSNorm:
class QKNormAttention(nn.Module):
def __init__(self, d_model: int, n_heads: int):
super().__init__()
self.n_heads = n_heads
self.d_head = d_model // n_heads
self.qkv = nn.Linear(d_model, 3 * d_model, bias=False)
self.out = nn.Linear(d_model, d_model, bias=False)
self.q_norm = nn.RMSNorm(self.d_head)
self.k_norm = nn.RMSNorm(self.d_head)
def forward(self, x):
B, T, C = x.shape
qkv = self.qkv(x).reshape(B, T, 3, self.n_heads, self.d_head)
q, k, v = qkv.unbind(2)
q, k = self.q_norm(q), self.k_norm(k) # 注意力前先归一化
q, k, v = [t.transpose(1, 2) for t in (q, k, v)]
attn = (q @ k.transpose(-2,-1) * self.d_head**-0.5).softmax(dim=-1)
return self.out((attn @ v).transpose(1,2).reshape(B, T, C))起源: 视觉 / 多模态模型(Dehghani 2023、Idefics、Chameleon)
LLM 中的采用: DCLM、OLMo 2、Gemma 2
技巧 3:Logit Soft-Capping
通过 tanh 对输出 logits 做软上限,防止其爆炸:
def soft_cap_logits(logits: torch.Tensor, cap: float = 30.0) -> torch.Tensor:
return cap * torch.tanh(logits / cap)它是可微的(不同于硬截断),但 tanh 压缩可能会略微影响表达能力。Gemma 2 使用了该技巧(输出 logits 的 cap=30,注意力 logits 的 cap=50)。
小结
| 技巧 | 目标 | 作用 | 模型 |
|---|---|---|---|
| Z-loss | 输出 softmax | 惩罚 log-partition function | PaLM, Baichuan 2, DCLM, OLMo 2 |
| QK Norm | 注意力 softmax | 在点积前归一化 Q/K | Gemma 2, DCLM, OLMo 2 |
| Logit soft-cap | 两者 | 通过 tanh 限制 logit 幅度 | Gemma 2 |
6. 注意力变体
推理瓶颈:KV Cache
在训练时,注意力可以沿序列并行计算——算术强度高,GPU 利用率也高。
但在自回归推理时,一次只能处理一个 token,而且必须缓存之前所有的 K/V 状态。此时增量计算的算术强度变为:
其中 n/d 这一项会随着序列长度增长——因此KV cache 的读取才是真正的瓶颈,而不是计算本身。
多头注意力(MHA)——基线
每个 n_heads 中的 head 都有自己的 Q、K、V。KV cache 大小为:2 × n_heads × seq_len × d_head × n_layers。
多查询注意力(MQA)[Shazeer 2019]
所有 query head 共享一个 K/V head。 KV cache 缩小 n_heads 倍。
class MultiQueryAttention(nn.Module):
def __init__(self, d_model: int, n_heads: int):
super().__init__()
self.n_heads = n_heads
self.d_head = d_model // n_heads
self.q_proj = nn.Linear(d_model, d_model, bias=False)
self.k_proj = nn.Linear(d_model, self.d_head, bias=False) # 单个 head
self.v_proj = nn.Linear(d_model, self.d_head, bias=False) # 单个 head
self.out = nn.Linear(d_model, d_model, bias=False)
def forward(self, x):
B, T, _ = x.shape
q = self.q_proj(x).reshape(B, T, self.n_heads, self.d_head).transpose(1, 2)
k = self.k_proj(x).reshape(B, T, 1, self.d_head).transpose(1, 2)
v = self.v_proj(x).reshape(B, T, 1, self.d_head).transpose(1, 2)
attn = (q @ k.transpose(-2,-1) * self.d_head**-0.5).softmax(dim=-1)
return self.out((attn @ v).transpose(1,2).reshape(B, T, -1))缺点: 困惑度会有轻微损失 [Shazeer 2019]。
分组查询注意力(GQA)[Ainslie et al. 2023]
一组 Q heads 共享一个 K/V head。它是 MHA 和 MQA 之间的折中旋钮。
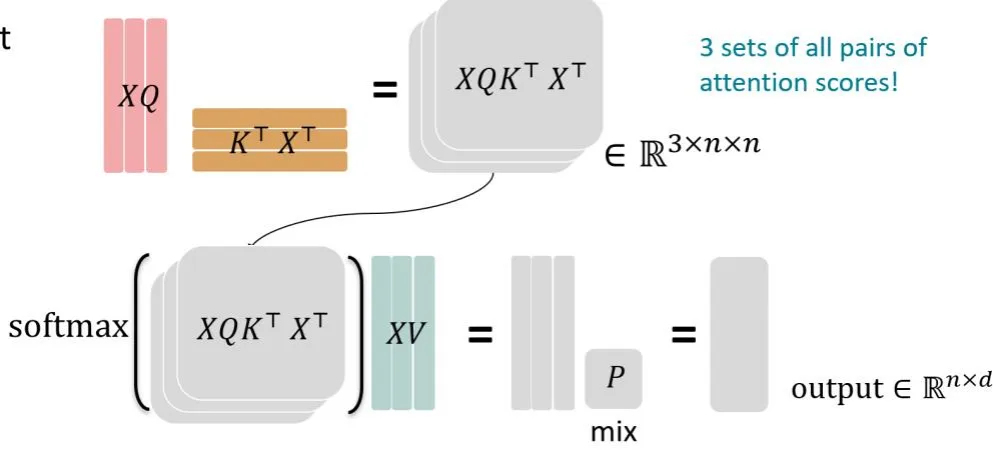
class GroupedQueryAttention(nn.Module):
"""
n_kv_heads=1 -> MQA
n_kv_heads=n_heads -> MHA
"""
def __init__(self, d_model: int, n_heads: int, n_kv_heads: int):
super().__init__()
assert n_heads % n_kv_heads == 0
self.n_heads = n_heads
self.n_kv_heads = n_kv_heads
self.n_rep = n_heads // n_kv_heads
self.d_head = d_model // n_heads
self.q_proj = nn.Linear(d_model, n_heads * self.d_head, bias=False)
self.k_proj = nn.Linear(d_model, n_kv_heads * self.d_head, bias=False)
self.v_proj = nn.Linear(d_model, n_kv_heads * self.d_head, bias=False)
self.out = nn.Linear(d_model, d_model, bias=False)
def forward(self, x):
B, T, _ = x.shape
q = self.q_proj(x).reshape(B, T, self.n_heads, self.d_head).transpose(1, 2)
k = self.k_proj(x).reshape(B, T, self.n_kv_heads, self.d_head).transpose(1, 2)
v = self.v_proj(x).reshape(B, T, self.n_kv_heads, self.d_head).transpose(1, 2)
k = k.repeat_interleave(self.n_rep, dim=1)
v = v.repeat_interleave(self.n_rep, dim=1)
attn = (q @ k.transpose(-2,-1) * self.d_head**-0.5).softmax(dim=-1)
return self.out((attn @ v).transpose(1,2).reshape(B, T, -1))| 变体 | Q heads | KV heads | KV Cache | 质量 |
|---|---|---|---|---|
| MHA | n | n | 基线 | 基线 |
| MQA | n | 1 | 缩小 n 倍 | 困惑度略有损失 |
| GQA | n | g(1 < g < n) | 缩小 n/g 倍 | 接近 MHA |
哪些模型使用 GQA: LLaMA 2/3(较大版本)、Mistral、Gemma、Falcon——多数大型 2024+ 模型。
滑动窗口注意力(SWA)
完整注意力复杂度是 O(n^2)。SWA 限制每个 token 只关注最近的 w 个 token,从而把复杂度降为 O(n×w)。
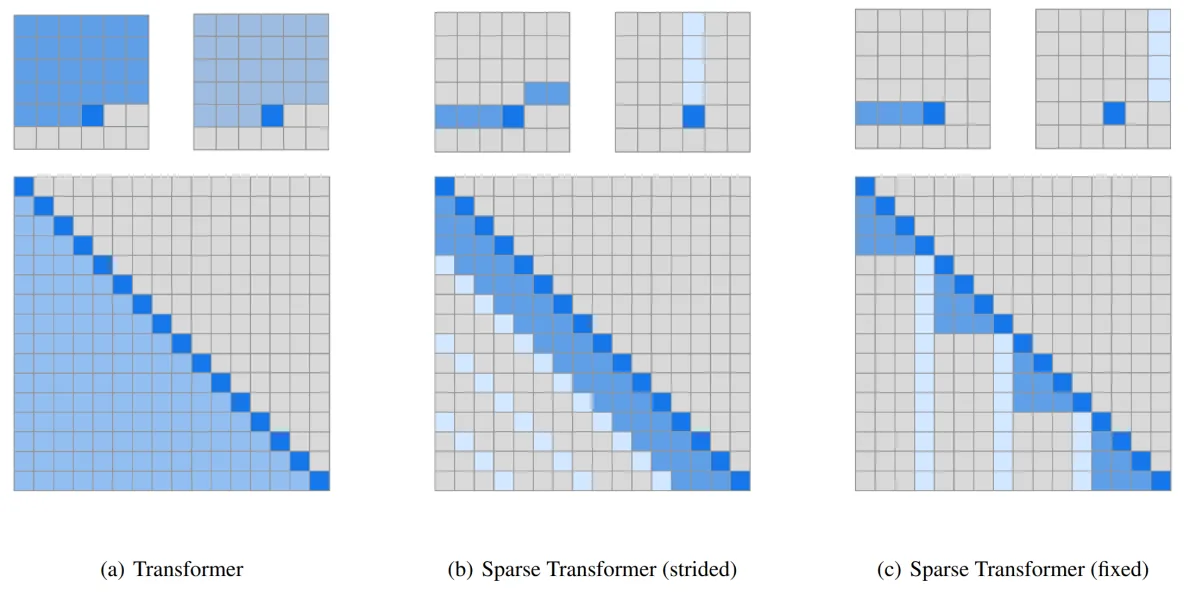
def sliding_window_mask(seq_len: int, window: int, device=None) -> torch.Tensor:
"""
返回形状为 (seq_len, seq_len) 的布尔 mask:True = 可关注,False = 被屏蔽。
同时结合了 causal mask 和窗口约束。
"""
i = torch.arange(seq_len, device=device).unsqueeze(1)
j = torch.arange(seq_len, device=device).unsqueeze(0)
causal = i >= j # 下三角(因果)
window = (i - j) < window # 位于窗口内
return causal & window当前最佳实践——Full + SWA 交替:
Layer 0: SWA (RoPE) ↘ 便宜,处理局部上下文
Layer 1: SWA (RoPE)
Layer 2: SWA (RoPE)
Layer 3: Full (NoPE) -> 昂贵,处理全局上下文——每 4 层一次
Layer 4: SWA (RoPE)
...- SWA 层高效处理短程上下文
- 稀疏的 full-attention 层负责长程依赖
- 有些模型中:SWA 用 RoPE,而 full attention 用 NoPE(不使用位置嵌入)
使用模型: Mistral 7B、LLaMA 4、Gemma、Cohere Command A
宏观结论
| 结论 | 置信度 | 为什么重要 |
|---|---|---|
| Pre-norm 是正确默认选择 | 高 | 梯度理论支持,加上几乎普遍采用 |
| RMSNorm 相比 LayerNorm 质量不差且实际更快 | 高 | 关键在内存带宽,不在 FLOPs |
| SwiGLU / GeGLU 很可能优于 ReLU | 中 | 提升小但稳定;GPT-3 没用它也表现很好 |
| d_ff = 4×(或 GLU 下 8/3×) | 高 | 这一范围附近存在较平坦最优区间 |
| GQA/MQA 关注的是推理效率,而不是困惑度 | 高 | KV cache 才是真正瓶颈 |
| 稳定性技巧(z-loss、QK norm)正在变成标准配置 | 中高 | 在前沿模型里越来越常见 |
| 在 LLM 中,weight decay 不只是防过拟合 | 中 | 它会通过 LR schedule 影响优化动态 |
元结论: 现代 LLM 架构并不是从第一性原理直接推导出来的——它们是几十个模型版本、无数消融实验之后留下来的经验幸存者。相比死记硬背哪个模型用了哪种技术,真正更耐用的理解是:每个选择背后的原因是什么,比如内存带宽、推理成本、梯度稳定性。
参考文献:Vaswani 2017 · Xiong 2020 · Su 2021(RoPE) · Shazeer 2020(SwiGLU) · Shazeer 2019(MQA) · Ainslie 2023(GQA) · Kaplan 2020(scaling laws) · Ivanov 2023(RMSNorm) · Narang 2020 · Andriushchenko 2023