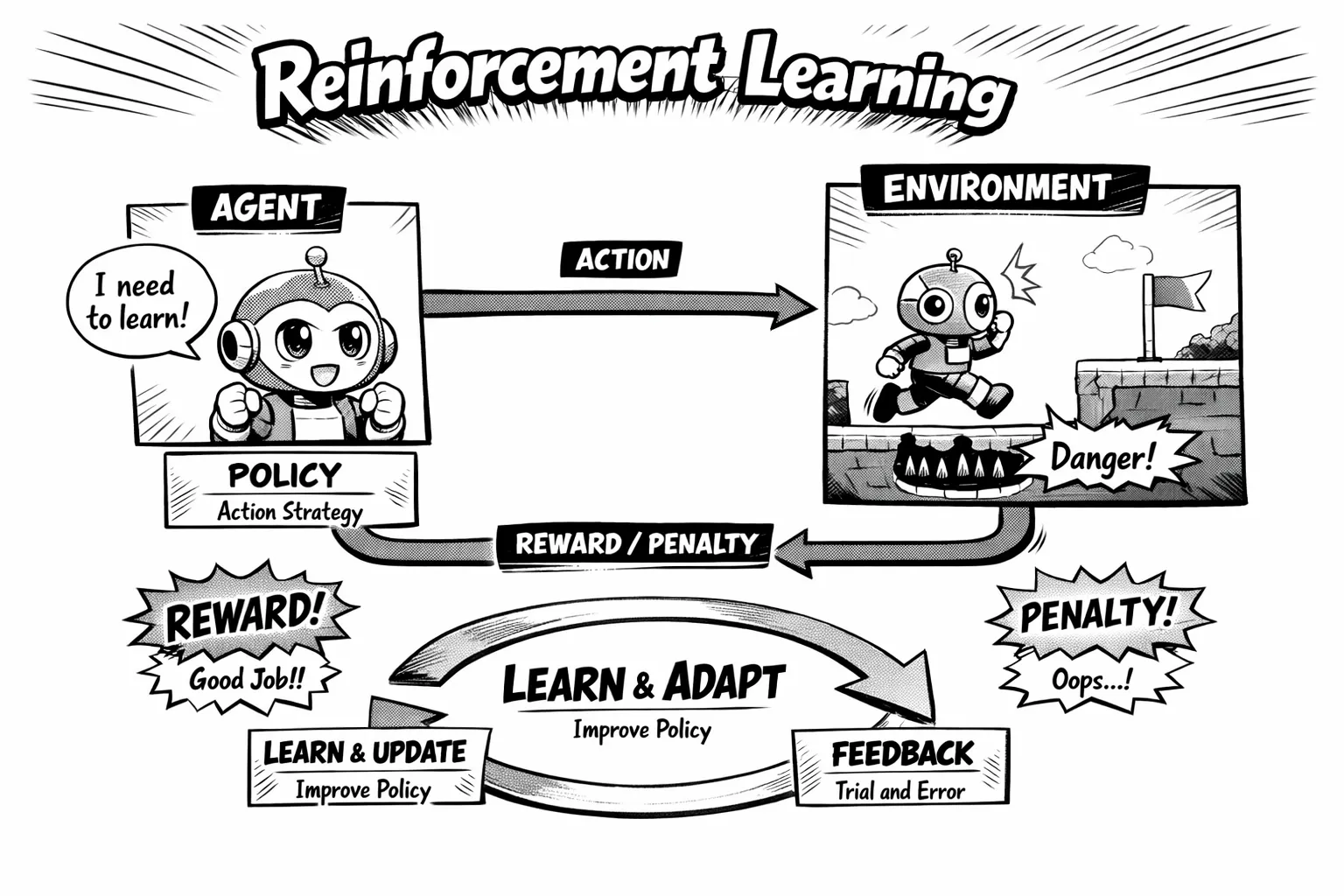
1.1 强化学习概述
强化学习(Reinforcement Learning,RL)是机器学习的一个重要分支,它提供了一个序贯决策(Sequential Decision Making)问题的统一视角。其核心讨论的问题是:智能体(Agent)如何在复杂、不确定的环境(Environment)中,通过与环境的交互,最大化它能获得的累积奖励。
如图 1.1 所示,强化学习由两部分组成:智能体和环境。
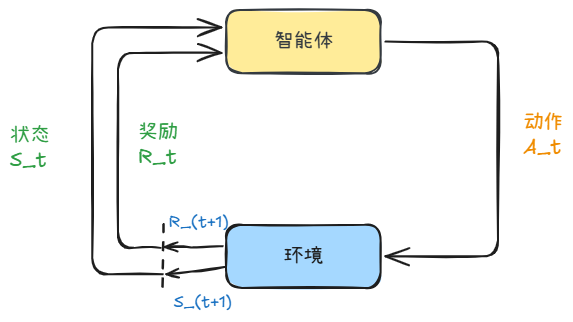
- 感知(Perception):智能体在环境中获取某个状态(State),从而了解自身所处的当前情境。
- 决策(Decision):智能体利用该状态输出一个动作(Action)。
- 执行与反馈:动作在环境中被执行,环境根据智能体采取的动作,输出下一个状态以及当前动作带来的奖励(Reward)。
智能体的终极目标是尽可能多地从环境中获取奖励。
1.1.1 强化学习与监督学习的本质区别
我们可以通过对比监督学习(Supervised Learning)来深入理解强化学习的独特性。
1. 数据的独立同分布假设 (i.i.d.)
- 监督学习:假设输入数据(如标注好的汽车、飞机图片)是独立同分布的。数据之间没有关联,且训练过程中数据分布固定不变。
- 强化学习:输入的是序列数据。智能体上一帧的观测与下一帧高度相关(如玩《Breakout》游戏),不满足独立同分布假设。更重要的是,数据分布由策略决定。
- 占用度量(Occupancy Measure):强化学习中的数据分布通常用占用度量来描述,它刻画了在给定策略下采样到某一“状态-动作对”的概率分布。
- 策略更新导致分布变化:一旦策略发生变化,智能体与环境交互产生的数据分布也会随之改变。这被称为“非平稳性”(Non-stationarity)。
2. 标签与反馈
-
监督学习:有一个全知的“监督者”告诉学习器正确的标签(Label)。如果预测错误(如把汽车预测为飞机),会立即得到修正。其目标函数通常是最小化预测与标签之间的误差:
-
强化学习:没有强监督者,只有奖励信号。
-
延迟奖励(Delayed Reward):环境不会告诉智能体当前动作是否“正确”,只会给出一个标量奖励。这个奖励往往是延迟的(例如在《Pong》游戏中,击球动作的奖励可能要等到球飞过对手底线时才产生)。
-
试错探索(Trial-and-Error):智能体需要通过不断尝试来发现哪些动作能带来长期收益。其目标是最大化在占用度量下的期望奖励:
-
总结:监督学习是优化模型以适应固定数据分布;强化学习是在动态环境中寻找一个策略,通过调整策略来优化数据分布,从而获得最大回报。
1.1.2 强化学习的例子
强化学习因其处理序列决策的能力,在许多领域超越了人类表现:
- 自然界:羚羊出生后通过试错学会站立和奔跑。
- 金融交易:股票交易策略根据市场反馈不断调整,以最大化收益。
- 游戏:DeepMind 的 AlphaGo 击败人类围棋顶尖棋手;在雅达利(Atari)的 Pong 游戏中,智能体学会了复杂的击球策略。
- 机器人控制:机械臂通过强化学习学会抓取不同形状的物体,甚至完成穿衣等精细操作。
1.1.3 强化学习的历史与深度强化学习
强化学习经历了从标准强化学习到深度强化学习(Deep Reinforcement Learning, DRL)的演变。
- 标准强化学习(如 TD-Gammon):依赖人工设计的特征(Feature Engineering),然后训练价值函数或策略。
- 深度强化学习:利用深度神经网络(如 CNN)自动提取特征,实现端到端(End-to-End)训练。类似于计算机视觉从传统特征提取(HOG/SIFT)转向深度卷积网络(AlexNet),DRL 直接从原始输入(如像素)输出动作,极大地提升了智能体的能力。
1.2 序列决策与环境交互
1.2.1 序贯决策的视角
与单轮预测任务不同,强化学习解决的是序贯决策问题。决策者的选择不仅影响即时结果,还会改变未来所处的状态,并对后续决策产生长期影响。因此,决策者必须对未来负责。
1.2.2 环境:动态随机过程
强化学习中的环境是一个动态的随机过程,这引入了双重随机性:
-
策略的随机性:智能体选择动作可能是随机的(如 )。
-
环境转移的随机性:环境根据当前状态和动作,依概率分布转移到下一状态:
1.2.3 马尔可夫决策过程 (MDP) 与 POMDP
在与环境交互中,历史轨迹由观测、动作、奖励序列组成:。
- 完全可观测(Fully Observed):当智能体能感知环境的所有状态时(),问题被建模为马尔可夫决策过程(MDP)。
- 部分可观测(Partially Observed):当智能体只能看到部分信息(如第一人称视角的扑克牌、自动驾驶传感器的有限视野)时,问题被建模为部分可观测马尔可夫决策过程(POMDP)。POMDP 由七元组 描述。
1.3 动作空间 (Action Space)
不同的环境决定了智能体动作的形式:
- 离散动作空间(Discrete Action Space):动作数量有限且可数。
- 例子:雅达利游戏(上、下、左、右)、围棋(落子位置)。
- 连续动作空间(Continuous Action Space):动作是实值向量,不可数。
- 例子:机器人关节的角度控制、自动驾驶的方向盘转角和油门力度。
1.4 智能体的三要素与类型
一个完整的强化学习智能体通常包含以下三个关键要素中的一个或多个:
1.4.1 策略 (Policy)
策略是智能体的行为模型,决定了在给定状态下采取什么动作。
- 随机性策略 (Stochastic Policy) :输出动作的概率分布。利于探索,常用于博弈。
- 确定性策略 (Deterministic Policy) :针对状态直接输出唯一动作。
1.4.2 价值函数 (Value Function)
价值函数是对未来累积奖励的预测(期望),用于评估状态的好坏。为了权衡即时与未来奖励,引入折扣因子 (Discount Factor) 。
-
状态价值函数 :
-
状态-动作价值函数 (Q函数) :
1.4.3 模型 (Model)
模型是智能体对环境运作方式的认知,包含:
- 状态转移概率:预测下一步状态 。
- 奖励函数:预测即时奖励 。
1.4.4 智能体的分类
- 根据学习内容分类:
- 基于价值 (Value-based):显式学习价值函数(如 Q-learning),策略通过价值函数隐式推导(如贪婪法)。
- 基于策略 (Policy-based):直接学习策略函数(如 Policy Gradient)。
- 演员-评论员 (Actor-Critic):同时学习策略(Actor)和价值函数(Critic)。
- 根据是否建立环境模型分类:
- 有模型 (Model-based):智能体在内部构建虚拟世界模型,通过“想象”和规划来寻找最优解。
- 免模型 (Model-free):不建立环境模型,直接通过与真实环境的交互试错来学习。目前大多数深度强化学习方法(如 DQN, PPO)属于此类,泛化性较好。
1.5 学习与规划 (Learning vs. Planning)
- 学习 (Learning):环境初始未知。智能体通过与环境交互,观测结果,逐渐改进策略。这是强化学习的核心。
- 规划 (Planning):环境模型已知(规则明确,如国际象棋)。智能体无需实时交互,通过计算和模拟即可寻找最优解(如蒙特卡洛树搜索)。
1.6 探索与利用 (Exploration vs. Exploitation)
强化学习面临的经典窘境:探索-利用窘境 (Exploration-Exploitation Dilemma)。
- 探索 (Exploration):尝试未知的动作,旨在发现可能带来更大长期回报的新策略。风险是可能得到负反馈。
- 利用 (Exploitation):执行当前已知的最优动作,以获取稳妥的奖励。风险是可能陷入局部最优,错过更好的机会。
K-臂赌博机 (K-armed Bandit) 是研究这一问题的经典模型。
- 仅探索:平均尝试所有摇臂,估计准确但收益低。
- 仅利用:只按目前最好的摇臂,可能错过潜在的“大奖”摇臂。
- 折中:如 -greedy 策略,以 的概率探索,以 的概率利用。
1.7 强化学习实验:OpenAI Gym
强化学习强调理论与实践结合。OpenAI 提供的 Gym 库是目前最通用的实验环境库。
1.7.1 Gym 基础使用
Gym 提供了标准化的接口(Env),包含 reset()(重置环境)、step()(执行动作)、render()(渲染画面)等方法。
安装:
pip install gym==0.25.2 pygame基本交互循环代码示例:
import gym
env = gym.make('CartPole-v0') # 构建环境
observation = env.reset() # 初始化状态
for _ in range(1000):
env.render() # 显示图形界面
action = env.action_space.sample() # 随机采样动作(探索)
# 执行动作,返回新状态、奖励、结束标志、调试信息
observation, reward, done, info = env.step(action)
if done:
observation = env.reset() # 回合结束,重置
env.close()1.7.2 案例:小车上山 (MountainCar-v0)
在 MountainCar 环境中,小车动力不足以直接冲上山顶,必须学会利用左侧山坡的势能“荡”上去。这是一个典型的需要延迟奖励和策略探索的任务。
查看环境空间:
import gym
env = gym.make('MountainCar-v0')
print('观测空间 = {}'.format(env.observation_space)) # Box(2,):位置和速度
print('动作空间 = {}'.format(env.action_space)) # Discrete(3):左、不动、右智能体交互逻辑:
我们可以编写一个简单的类来封装智能体的行为(decide)和学习过程(learn)。在测试阶段,智能体通过 decide 方法根据观测输出动作,并在环境中循环执行 step 直到 done 为 True。
通过 Gym 库,研究者可以快速验证算法在离散控制(如 CartPole)或连续控制(如 MuJoCo)任务上的性能。学术界通常关注 100 个回合的平均奖励来评估智能体的表现。