站点能正常访问之后,我接着做的一件事,就是让 Google 能尽快发现并收录这些页面。
一开始我以为这件事很简单,无非就是去 Search Console 提交一下网址。 结果真正做下来才发现,“网站能打开” 和 “网站能被 Google 正常收录” 完全是两回事。
前者只是说明用户能访问,后者要求的是:
- Google 能访问到你的站点
- 爬虫不会被你自己挡住
- 页面路径能被发现
- 站点地图和 robots 配置正确
- 域名验证、收录提交、后续排查都要跟上
这篇文章我就按我自己实际做的顺序,把整个过程完整整理一下。 如果你也是 腾讯云服务器 + Next.js + Nginx 部署,可以直接照着检查。
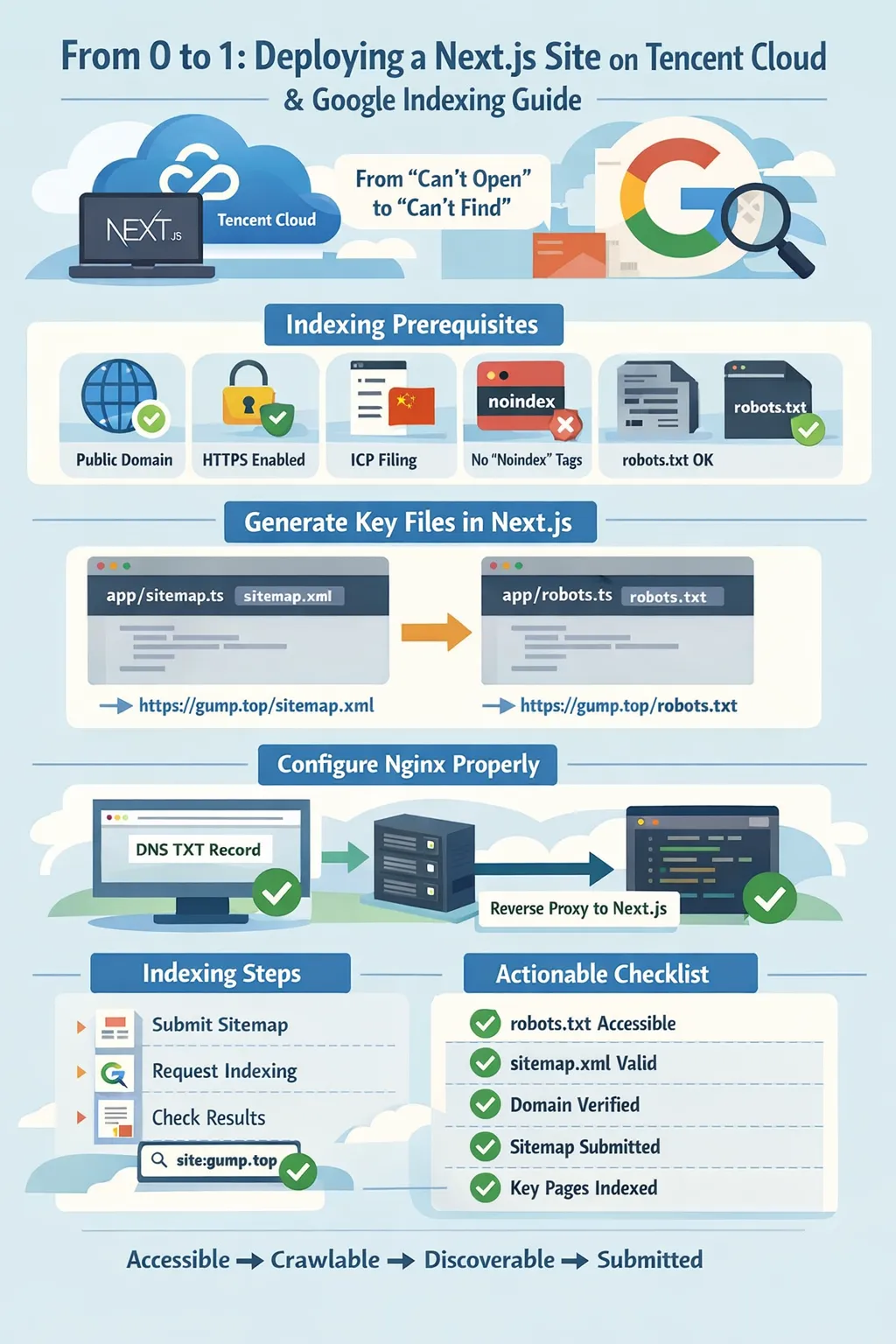
一、先说结论:Google 收录的核心路径到底是什么
在真正动手之前,先把这件事想清楚。
Google 收录一个站点,大致会经过这几步:
网站可访问 → 爬虫可抓取 → 页面可发现 → 主动提交 → 后续观察索引状态
很多人会卡在“我明明提交了,为什么还没收录”,本质上就是前面的某一步没打通。 尤其是自己部署的网站,最常见的问题根本不是 Search Console,而是:
- 域名没配好
- HTTPS 不完整
- robots 或 meta 配置挡住了爬虫
- sitemap 没生成出来
- Nginx 没把
/robots.txt和/sitemap.xml正确转发出去
所以我的建议是,不要一上来就去提交收录。 先把“地基”打好,再做 Search Console,这样效率最高。
二、收录前提:先把网站的基础条件补齐
1. 必须有域名,不要只用 IP
这一点虽然很基础,但确实有人会忽略。
Google 对站点的识别,本质上还是围绕域名来的。 如果你的网站现在还是通过服务器 IP 直接访问,比如:
http://123.123.123.123那后续做 Search Console、做 sitemap、做 robots、做 canonical,都会很别扭。 更关键的是,IP 形式本身就不适合长期作为正式站点入口。
所以第一步一定是先确认:
- 已经有自己的公网域名
- 域名已经正确解析到腾讯云服务器
- 线上访问统一走域名,而不是 IP
比如像这样:
https://gump.top这个域名,后面会反复出现在:
- sitemap 地址里
- robots 地址里
- Search Console 资源验证里
- canonical 和 SEO 配置里
也就是说,域名是整个收录体系的锚点。
2. HTTPS 必须可用,而且最好全站统一
第二个基础条件是 HTTPS。
今天如果你的网站还停留在纯 HTTP,Google 不是说一定不收录,但整体信任度、规范性、长期维护性都会差很多。 而且 Search Console 里不同协议前缀也会被视为不同资源,这会让你后续管理起来很麻烦。
我自己的建议是:
- 直接把站点统一成
https://你的域名 - HTTP 请求跳转到 HTTPS
- 不要让一部分页面是 HTTP,一部分页面是 HTTPS
也就是尽量避免下面这种混用情况:
http://gump.tophttps://gump.tophttp://www.gump.tophttps://www.gump.top
如果这些地址都能打开,但又没有统一跳转,那搜索引擎会把它们视为不同入口,轻则权重分散,重则造成重复内容判断。
上线之后你至少要手动访问一次:
https://你的域名确认浏览器地址栏没有证书错误、没有“不安全”的提示,页面能稳定打开。
3. 如果服务器在中国大陆,要先完成备案
这一点是腾讯云场景里绕不过去的。
如果你的服务器部署在中国大陆,那么域名要完成 ICP 备案。 不备案最直接的问题不是“Google 不收录”,而是访问链路本身可能就不稳定或者受限。
而搜索引擎能不能收录,前提永远是:它得先访问到你的页面。 如果页面本身经常打不开,或者某些链路下访问异常,那就会直接影响抓取。
所以这一项不要抱侥幸心理,尤其是正式站点:
- 大陆服务器 → 做备案
- 域名已经解析 → 检查备案是否生效
- 站点已经上线 → 再去做收录
这一步虽然和代码没关系,但它是 SEO 的基础设施问题。 基础设施没补齐,后面做再多配置都很难顺。
4. 页面里不要出现 noindex
这个坑其实挺隐蔽的,因为很多人平时根本不会去看页面源码。
只要你的页面里带了:
<meta name="robots" content="noindex">那就等于你在明确告诉搜索引擎:这个页面不要收录。
有时候这不是你主动写的,而是:
- 开发环境遗留配置
- 某个 SEO 组件默认带的
- 模板复制时忘了删
- 预发布环境和生产环境逻辑没分开
所以在准备收录前,我建议你一定做一遍检查:
- 打开站点页面
- 右键查看网页源代码
- 搜索
noindex
如果搜到了,先把它处理掉,再继续。
这一点看起来小,但它属于那种“你后面折腾半天 Search Console,结果问题居然在这里”的典型坑。
三、Next.js 里怎么生成 sitemap.xml
基础条件确认完之后,下一步就是让 Google 更容易“发现”你的页面。
最直接的办法,就是生成站点地图,也就是 sitemap.xml。
如果你用的是 Next.js App Router,这件事做起来其实很舒服。
我没有额外引第三方库,直接用的是内置方案:app/sitemap.ts。
它的好处是很明显的:
- 写法简单
- 跟项目结构在一起,维护方便
- 可以静态返回,也可以动态拼接
- 生成结果直接挂到
/sitemap.xml
也就是说,你只要把这个文件写好,线上就会自动生成:
https://你的域名/sitemap.xml1. 基础写法
先看一个可以直接用的最小版本。
import type { MetadataRoute } from "next";
const siteUrl = process.env.NEXT_PUBLIC_SITE_URL || "https://gump.top";
export default async function sitemap(): Promise<MetadataRoute.Sitemap> {
return [
{ url: `${siteUrl}/`, changeFrequency: "weekly", priority: 1 },
{ url: `${siteUrl}/blog`, changeFrequency: "daily", priority: 0.9 },
{ url: `${siteUrl}/reading`, changeFrequency: "weekly", priority: 0.8 },
{ url: `${siteUrl}/projects`, changeFrequency: "weekly", priority: 0.8 },
{ url: `${siteUrl}/travel`, changeFrequency: "weekly", priority: 0.8 },
];
}这段代码的意思其实很直白:
siteUrl:站点根域名- 返回一个数组,每一项就是一个要进入 sitemap 的页面
- 每个页面可以附带更新频率和优先级
这里我建议一定使用环境变量去维护域名,而不是把地址写死到多个文件里。 后面如果域名变了,或者你还有预发布环境,就不会改得很痛苦。
比如生产环境里配置:
NEXT_PUBLIC_SITE_URL=https://gump.top这样 sitemap.ts 和 robots.ts 都可以复用这一个变量。
2. 为什么 sitemap.xml 这么重要
很多人觉得 sitemap 就是“有最好,没有也行”。 理论上没错,因为 Google 也可以靠页面里的链接自己爬。
但对个人站、博客站、作品集站来说,sitemap 的意义非常大:
第一,它会告诉搜索引擎: 我有哪些页面,优先可以从这里开始看。
第二,对于一些层级较深、首页不容易直接点到的页面,sitemap 会提升“被发现”的概率。
第三,你后面在 Search Console 提交 sitemap 后,Google 会更快建立站点页面的整体认知。
所以我会把 sitemap 当成必做项,而不是可选项。
3. 动态页面一定要进 sitemap
如果你的网站不只是几个固定页面,而是带有文章详情页、项目详情页、标签页,那就不能只返回静态路由。
比如我自己的实际场景里,除了这些固定页:
//blog/reading/projects/travel
还会有很多动态页面,例如:
/blog/[slug]/reading/[slug]/projects/[slug]/travel/[slug]/blog/tag/[slug]/blog/series/[slug]
这些页面如果不进 sitemap,Google 也不一定完全发现不了,但发现效率和完整度会差很多。 尤其是标签页、系列页这种“靠结构组织内容”的页面,很多时候比文章详情页更需要主动暴露出来。
所以更完整的做法是:
- 读取你的文章、标签、系列数据
- 在
sitemap()里拼出完整 URL - 一起返回
你文章是从 MDX、数据库、CMS 还是本地文件读取都没关系,思路是一样的。
4. 写 sitemap 时我自己的几个习惯
这里顺手说几个我自己会注意的点。
域名一定要是生产域名
别让 sitemap 里出现这种东西:
http://localhost:3000/blog/xxx或者:
https://test.gump.top/blog/xxx如果生产环境里 NEXT_PUBLIC_SITE_URL 没配好,就很容易生成错地址。
这个问题你代码本地看不出来,但线上 sitemap 一提交就会出问题。
不要把明显不该收录的页面塞进去
比如这些路径,一般就不应该进 sitemap:
- 后台管理页
- 登录页
- 内部测试页
- 无实际内容价值的接口页
- 重定向中间页
sitemap 不是“把所有路由都扔进去”,而是“把你希望搜索引擎重点发现和理解的页面扔进去”。
生成完一定要打开看一眼
不要写完就默认它没问题。 上线之后第一件事就是访问:
https://你的域名/sitemap.xml确认至少这几件事:
- 页面能打开,不是 404
- 返回的是 XML,不是 HTML 错误页
- 里面的 URL 是正确域名
- 动态页面确实被带出来了
这一步非常重要,因为很多问题根本不是逻辑错,而是部署后路由没通。
四、Next.js 里怎么生成 robots.txt
除了 sitemap,另一个必须补的文件就是 robots.txt。
它的作用不是“帮助你收录”,而是告诉搜索引擎:
- 哪些内容可以抓
- 哪些内容不要抓
- sitemap 在哪里
在 Next.js App Router 里,这个也有内置方案。 对应文件就是:
app/robots.ts很多人第一次看到会疑惑: 这个 ts 文件是不是等价于 robots.txt?
答案是:是的。
它不是你手动写一个静态文本文件,而是由 Next.js 在运行时帮你生成 robots.txt 内容。
最终外部访问到的路径依然是:
https://你的域名/robots.txt1. 一个可以直接用的示例
import type { MetadataRoute } from "next";
const siteUrl = process.env.NEXT_PUBLIC_SITE_URL || "https://gump.top";
export default function robots(): MetadataRoute.Robots {
return {
rules: [
{
userAgent: "*",
allow: "/",
disallow: ["/admin", "/api/admin/"],
},
],
sitemap: `${siteUrl}/sitemap.xml`,
host: siteUrl,
};
}这段配置表达的意思是:
- 对所有爬虫生效:
userAgent: "*" - 默认允许抓取全站:
allow: "/" - 但不允许抓取后台管理路径和管理接口
- 同时告诉爬虫 sitemap 在哪里
这个写法对博客、作品集、内容站来说已经够用了。
2. robots.txt 最容易犯的几个错
错误一:把全站给拦了
有些人开发阶段为了防止测试站被抓,写过这样的规则:
User-agent: *
Disallow: /结果上线时忘了改,等于直接告诉所有搜索引擎:别抓我的站。
所以生成完 robots.txt 之后,一定要自己打开看看内容。
别只看“这个路径能访问”,还要看“内容是不是自己想要的”。
错误二:robots 允许抓取,但页面 meta 又写了 noindex
这是个典型的“双层冲突”。
也就是说,你的 robots.txt 看起来没问题,允许抓取;
但页面 HTML 里却写着:
<meta name="robots" content="noindex">那结果还是不会正常收录。
所以你要明确区分两件事:
robots.txt:控制能不能抓noindex:控制抓了之后要不要进索引
这两个不是一回事。
错误三:忘了在 robots 里声明 sitemap
严格来说,不声明也不是绝对不行。
但既然都已经生成了 sitemap,那在 robots.txt 里顺手告诉爬虫它的位置,几乎没有成本,却能增加发现效率。
所以这句最好带上:
sitemap: `${siteUrl}/sitemap.xml`五、部署到腾讯云后,Nginx 才是真正容易出坑的地方
到这里,代码层面其实已经差不多了。 但我自己实际踩下来,真正容易翻车的地方,不是在 Next.js,而是在 Nginx 转发。
很多时候你本地开发完全正常:
app/sitemap.ts写好了app/robots.ts写好了
你以为线上就一定没问题。 结果一上线发现:
/robots.txt404/sitemap.xml404- 或者返回了错误的静态资源
- 或者压根没走到 Next 服务
这就是因为:Next.js 代码写对了,不代表 Nginx 一定把请求转发对了。
1. 你要确认的不是“项目启动了”,而是“这两个路径能通”
最关键的两个地址是:
https://gump.top/robots.txt
https://gump.top/sitemap.xml这两个地址要分别打开检查。 不是首页能开就算完事,必须单独验证。
如果这两个地址返回 404,问题通常有几种:
- Nginx 只代理了首页和常规页面,没有正确代理这些特殊路径
- 某些静态资源规则把它们拦截掉了
- 你把站点当静态站部署,但这些文件实际上是 Next 运行时生成的
- 反向代理目标端口不对
- Next 服务没正确读取生产环境变量
2. 为什么 robots.txt / sitemap.xml 会被 Nginx 误伤
很多人写 Nginx 配置时,会加一些静态文件规则,比如:
/assets//images//favicon.ico
或者直接对部分后缀做特殊处理。
如果规则写得比较粗糙,就可能把 robots.txt 和 sitemap.xml 当成静态文件去找,结果静态目录里又没有,于是直接 404。
但在 App Router 这种方案里,robots.txt 和 sitemap.xml 很多时候不是磁盘上的现成文件,而是由 Next.js 在运行时生成的。
这意味着它们应该走到 Next 服务,而不是被 Nginx 自己“截胡”。
所以部署时一定要确认:
/robots.txt请求能到 Next/sitemap.xml请求能到 Next- 没被静态文件 location 规则提前匹配掉
3. 生产环境域名变量也要同步好
我上面代码里一直在用这个变量:
NEXT_PUBLIC_SITE_URL=https://gump.top这在本地开发时你可能已经配好了,但上线之后,生产环境未必真的有这个值。
如果没配好,最常见的结果是:
- sitemap 里 URL 变成默认值
- robots 里 sitemap 地址不对
- 域名变成测试环境地址
- 有时候甚至带着
localhost
所以一定要在生产环境再次确认:
- 环境变量确实生效
- 值是完整的 HTTPS 域名
- 不要漏
https:// - 不要在末尾多带斜杠,避免拼路径时出现双斜杠
4. 我建议上线后按这个顺序验收
网站部署完成之后,我会手动做一遍最基本的验收:
先看首页:
https://gump.top再看 robots:
https://gump.top/robots.txt再看 sitemap:
https://gump.top/sitemap.xml这三个都能正常访问,再去做 Search Console。 不然你很容易在 Google 那边浪费时间,但真正的问题其实在线上配置。
六、Google Search Console 这一步到底该怎么配
前面的工作做完之后,就可以进入 Google Search Console 了。
很多人会把这一步理解成“提交网址给 Google”。 但其实 Search Console 做的不只是提交,它更像是你和 Google 沟通网站状态的后台。
你后面会用它来做这些事:
- 验证你是这个域名的所有者
- 提交 sitemap
- 检查某个页面是否已收录
- 观察哪些页面没被索引
- 查看是抓取问题、重复问题,还是质量问题
所以这一步不是形式,而是后续排查的核心工具。
1. 添加资源时,我更建议直接选 Domain
Search Console 添加资源时,通常有两种方式:
DomainURL prefix
我自己的建议很明确:优先选 Domain。
原因很简单,它覆盖更完整。
比如你做的是 Domain 类型,那它会统一覆盖这些情况:
http://gump.tophttps://gump.tophttp://www.gump.tophttps://www.gump.top
也就是说,域名级别的各种协议和子域变体都会被一起纳入。
而如果你选的是 URL prefix,那你填什么就只认什么。
比如你填了:
https://gump.top那它并不会自动覆盖 http://gump.top 或 https://www.gump.top。
对长期维护来说,Domain 显然更省心,也更规范。
2. 域名验证通常就是加一条 DNS TXT 记录
选 Domain 之后,Google 会给你一条验证记录。
格式大概长这样:
google-site-verification=xxxxx接下来要做的事,不是在服务器里改东西,而是去腾讯云 DNS 解析里加一条 TXT 记录。
通常我会这样填:
- 记录类型:
TXT - 主机记录:
@ - 记录值:Google 提供的完整验证字符串
- TTL:默认即可
这里最容易出错的,不是技术难,而是操作细节:
第一,别加错地方
你得确认这个域名的 DNS 现在到底托管在哪。 有的人域名在腾讯云买的,但 DNS 其实在 Cloudflare;也有人服务器在腾讯云,但域名解析在别的平台。
Google 验证查的是当前生效的 DNS,不是你以为的那个平台。 所以 TXT 记录一定要加到实际生效的 DNS 服务商那里。
第二,主机记录通常填 @
如果你做的是顶级域名验证,比如 gump.top,那主机记录一般就是:
@不要想当然填成:
wwwgump.top- 留空
除非平台特别要求,否则多数情况就是 @。
第三,记录值要完整复制
Google 给你的验证值,不是让你手动摘一部分。 整段都要原样复制进去,例如:
google-site-verification=xxxxx不要只填后面的 xxxxx。
3. 验证失败时我会先排查这几项
如果你加完记录后回 Search Console 点 Verify,结果失败,不要着急。
这个场景非常常见,一般就是下面几个原因。
原因一:TXT 记录加错平台了
这是最常见的。 你以为 DNS 在腾讯云,实际上域名当前生效的是别家 DNS。
原因二:主机记录填错了
该填 @,结果填成了 www,那 Google 查顶级域名时当然查不到。
原因三:复制不完整
有时候中间多了空格、少了前缀、少了字符,都会导致验证失败。
原因四:DNS 还没生效
DNS 不是你点保存就立刻全球同步。 有时候几分钟就好了,有时候要十几分钟甚至更久。
所以如果我确认记录没填错,但还是失败,我通常不会立刻瞎改,而是先等一会儿再验证。
4. 怎么确认 TXT 记录到底生效了没有
这里我一般会直接用在线 DNS 查询工具查一下,比如 dnschecker 这类网站。
查顶级域名的 TXT 记录,看 Google 那条验证值有没有传播出来。
如果查询结果里已经能看到你加的那条 TXT,那再回 Search Console 验证,成功率就会高很多。
这一步的意义是: 不要把问题卡在“我感觉已经配好了”,而是直接查实际解析结果。
七、验证通过后,不要停,立刻做两件事
很多人做到域名验证成功,就以为差不多结束了。 其实这才刚开始。
验证通过后,我建议立刻做两件事,而且顺序不要拖:
- 提交 sitemap
- 提交核心页面做索引请求
1. 先提交 sitemap
进入 Search Console 后,找到:
Indexing -> Sitemaps然后把你的 sitemap 地址填进去:
https://gump.top/sitemap.xml提交后,Google 就会开始根据这份站点地图去发现页面。
为什么我会把这一步放得这么靠前? 因为 sitemap 提交成功之后,Google 对你整个站点结构的理解会更完整。 它不只是看你单独提交的某一个页面,而是能顺着 sitemap 去看全站有哪些重要 URL。
这对博客站尤其有用,因为博客通常页面很多,而且会持续增长。
2. 再用 URL Inspection 提交核心页面
sitemap 提交完之后,不代表所有页面都会马上被抓。 所以我通常还会手动补一轮重点页面。
具体做法是,在 Search Console 顶部用 URL Inspection 逐个检查并请求收录。
我自己会优先提交这几类页面:
第一类:首页
也就是:
/首页通常是全站权重最高的入口页,也是站点结构中最重要的页面。
第二类:栏目页 / 聚合页
比如:
/blog
/projects
/reading
/travel这些页面本质上是内容总入口。 Google 抓到这些页之后,更容易继续理解你站点的内容组织方式。
第三类:重点内容页
比如你最想让别人搜到的 5 到 10 篇内容:
- 高质量文章
- 项目介绍页
- 有明显搜索价值的专题页
- 已经做了内链和标题优化的页面
我不建议一上来就疯狂提交几十上百个 URL。 对新站来说,先把最核心的一批页面喂给 Google 就够了。 后续它自然会沿着站内链接继续抓。
八、为什么“已经提交了”还是没收录
这是几乎每个人都会遇到的问题。
页面已经能访问了,Search Console 也验证过了,sitemap 也提交了,为什么还是没进索引?
这时候最重要的一件事是: 不要靠猜,直接看 Search Console 的 Pages 报告。
路径大概在:
Indexing -> Pages这里会直接告诉你,Google 对这些页面的判断是什么状态。
1. Discovered - currently not indexed
这个状态的意思是:
Google 已经发现这个页面了,但暂时还没真正去抓取或者处理。
这通常出现在:
- 新站
- 新页面
- 站点整体抓取优先级还不高
- 页面很多,但权重和抓取预算还没建立起来
这个状态不一定是你配置错了。 很多时候只是因为站点还比较新,Google 还在排队处理。
如果是这个状态,我通常会做的不是瞎改,而是:
- 确认 sitemap 没问题
- 确认内链能到达这个页面
- 确认页面质量确实足够
- 稳定更新内容,等一段时间再观察
2. Crawled - currently not indexed
这个状态更值得重视。 它的意思是:
Google 已经抓过这个页面了,但最后决定暂时不收录。
这通常说明,不是“它没看到”,而是“它看了之后觉得暂时没必要进索引”。
常见原因包括:
- 页面内容太薄
- 页面价值不明显
- 内容和别的页面太像
- 标题、描述、正文都比较模板化
- 页面虽然存在,但没什么独特信息
这个状态下,继续疯狂点“请求编入索引”通常没太大意义。 更有效的做法是回到页面本身,提升内容质量和差异化。
说白了,Google 不是只看你配没配好,还会看: 这个页面值不值得进索引。
3. Blocked by robots.txt
这个就比较直接了。
意思是你自己在 robots.txt 里把它拦掉了。
这时候就回头去检查:
- 规则有没有写太宽
- 是否把应该开放的目录也屏蔽了
- 是否误把某个内容目录整个 disallow 掉了
这种问题属于配置性错误,修起来一般不复杂。
4. Duplicate without user-selected canonical
这个状态说明 Google 觉得这个页面和别的页面内容高度相似,但你没有明确告诉它“哪个才是主版本”。
这种情况经常发生在:
- 同一内容有多个访问路径
- 协议或域名未统一
- 列表页分页、筛选页结构太像
- 参数 URL 和正常 URL 同时可访问
这类问题本质上不是“收录慢”,而是“搜索引擎不确定该收哪一个”。
所以如果你看到这个状态,优先排查:
- 是否存在多个 URL 指向同一内容
- 域名和协议有没有统一跳转
- canonical 是否正确设置
- 页面结构是否产生了大量重复版本
九、我自己总结的几个“加快收录”的有效做法
说“加快收录”,很多人会去找各种偏门技巧。 但我自己做下来,真正有效的其实都很朴素,而且长期也更稳。
1. 持续更新高质量内容,而不是一次性堆页面
Google 更喜欢一个持续活跃的网站,而不是一次性生成很多页面然后长期不动。
所以比起一口气发 50 个低质量页面,我更建议:
- 稳定输出
- 每篇内容有明确主题
- 页面信息完整
- 标题、正文、结构都认真写
特别是博客站,持续更新本身就是一种信号。 它会告诉搜索引擎:这个站点是活的,不是临时搭出来摆着的。
2. 内链结构一定要清晰
这一点非常关键,而且常常被忽视。
Google 发现页面,除了靠 sitemap,还靠页面之间的链接。 如果你的内容页发出去之后,除了手动输入地址,站内几乎没有入口能点到它,那它被发现和理解的效率一定会差很多。
所以我会尽量保证:
- 首页能到各个主栏目
- 栏目页能到所有重要内容页
- 文章页之间有相关推荐或上下文链接
- 标签页、系列页能把内容组织起来
对搜索引擎来说,好的内链结构等于告诉它: 这些页面之间是什么关系,哪些页面更重要。
3. 适当做外部入口,引导第一次抓取
如果你的网站是新站,没有历史权重,也没有什么外部链接,那 Google 发现它的速度往往不会特别快。
这时候我会做一些很自然的外部曝光,比如:
- GitHub 个人主页放站点链接
- 知乎、掘金、X、即刻、技术社区个人介绍里挂域名
- 在相关文章或项目页里引用自己站点内容
这不是为了“刷外链”,而是为了给搜索引擎更多入口,让它更容易顺着外部页面发现你的站点。
4. 页面标题和描述别写得太模板化
这个问题很多博客很容易中招。
比如所有页面标题都长得差不多:
- 我的博客 - 首页
- 我的博客 - 文章
- 我的博客 - 项目
- 我的博客 - 阅读
或者文章详情页全是机械拼接,没有足够区分度。
这样做的坏处是,搜索引擎很难快速理解不同页面之间的差异。 严重一点,还会让整体页面信号显得很弱。
所以我自己的习惯是:
- 每个栏目页有清晰独立的标题
- 每篇文章标题尽量准确表达主题
- description 不要完全复用模板
- 避免大量“只有词序不同,信息几乎一样”的页面标题
十、把这件事变成日常维护,而不是一次性配置
很多人第一次做收录,会把它当成一个“配置任务”:
- robots 写了
- sitemap 有了
- Search Console 验证了
- 好,结束
其实不是。
收录本质上是一个持续过程。 你的网站内容会更新,页面会变多,站点结构也可能会调整,所以这件事最好变成一个固定检查项。
我现在会把它当成一个轻量的周期性维护动作来做。
一份真正可执行的 Checklist
这是我自己整理下来最实用的一版,你可以直接照着过一遍。
基础访问层
- 域名已经解析到线上服务器
- 网站统一通过 HTTPS 正常访问
- 如果服务器在中国大陆,备案已经完成
抓取控制层
- 页面源码里没有
noindex robots.txt可以正常访问robots.txt没有误拦截全站或重要目录
页面发现层
sitemap.xml可以正常访问sitemap.xml里包含重要栏目页和核心内容页- 动态页面已经被正确加入 sitemap
Search Console 层
- 域名资源验证通过
- 已提交 sitemap
- 首页、栏目页、重点页面已手动请求索引
后续观察层
- 每周看一次 Pages 报告
- 遇到未收录状态时,先看原因再处理
- 持续更新内容并优化内链结构
十一、我自己的最终理解:Google 收录不是“提一下网址”这么简单
做完这一整套之后,我对这件事的理解其实比一开始清晰很多。
让一个腾讯云上部署的 Next.js 网站被 Google 正常检索,关键并不是某个单点操作,而是一整条链路是否通顺。
真正有效的路径是:
网站能访问 → 爬虫能抓 → 页面能被发现 → 你主动提交 → 后续持续优化
这几个环节里,任何一个地方掉链子,都会让你产生一种错觉:
“我明明都提交了,为什么还是没收录?”
但只要你按顺序排查,其实问题通常都能定位出来。
十二、本文涉及到的 Next.js 方案为什么我最后选它
最后补一句我自己的选择理由。
在 Next.js App Router 里,用:
app/sitemap.tsapp/robots.ts
来管理这两个文件,我觉得是目前最省心的方案。
原因很简单:
- 和项目代码放在一起,维护直观
- 不需要额外再手动维护静态文件
- 动态页面很好接入
- 部署后路径固定,Search Console 也容易接
如果你的网站后面内容越来越多,这种方案的维护成本会比手工方式低很多。
结尾
如果你现在已经做到 Google Search Console 的 DNS 验证 这一步,那其实已经很接近了。 接下来最应该做的,不是继续焦虑“什么时候收录”,而是按顺序把这几件事补完:
- 确认
robots.txt和sitemap.xml线上都能打开 - 验证通过后立刻提交 sitemap
- 把首页、栏目页和重点内容页做一次 URL Inspection
- 后面定期看 Pages 报告,不要盲猜
只要前面的基础配置没问题,剩下的就是让 Google 更快理解你的网站,而不是从“看不见你的网站”开始。